13-5. 서포트벡터머신 (분류 모델)
서포트벡터머신(SVM) :
- 판별분석처럼 범주를 나눠주는 결정경계선을 찾아 관측치의 범주를 예측하는 모델
- 이진 분류에만 사용 가능하지만 비선형 데이터에서 높은 정확도를 보이며 과적합되는 경향도 적은 모델

서포트 벡터 : 결정경계선의 위치와 각도를 정해줄 수 있는 기준이 되는 관측치
- SVM에서는 서포트 벡터만으로 결정경계선을 정하게 되며 결정경계선과 서포트 벡터와의 거리가 마진이 됨.
- SVM에서는 거리를 기준으로 모델을 만들기 때문에 반드시 데이터 정규화나 표준화를 해주어야 함.

독립변수가 k개 일 때, 최적의 결정경계선을 찾기 위해서는 최소 k - 1개의 서포트 벡터가 필요.
<결정경계선 표현>
WX + b = 0
W: 가중치 벡터를 의미하며 독립변수 수에 따라 {w1, w2, … ,wk}로 이루어짐.
X: 각 독립변수
b: 편향값
결정경계선에서 해당 수식의 값이 0이기 때문에 경계선 위쪽에 있는 관측치는 0보다 크고, 경계선 아래쪽에 있는 관측치는 0보다 작음.


유클리드 거리 공식을 통해 결정경계선에서 마진까지의 거리를 구할 수 있음


하드 마진 : 이상치가 있는 경우, 이상치를 허용하지 않는 것
→ 과적합 문제가 발생할 수 있어 어느 정도 이상치를 허용해 주면서 마진을 최대화하는 방법을 사용(소프트 마진)
→ C와 Gamma : 이를 조절하는 매개변수
- C값을 낮게 설정하면 이상치를 일부 허용하는 결정경계선을 만듦.
- Gamma는 하나의 관측치가 영향력을 행사하는 거리를 조절하는 매개변수
→ 커널 기법: 기존의 데이터를 고차원 공간으로 확장해 결정경계선을 만들어내는 방법이며 가장 성능이 좋은 커널 기법으로는 가우시안 커널이 있음.


<Gamma>
Gamma값이 커질수록 가우시안 분포의 표준편차가 작아지며 관측치가 영향력을 행사하는 거리가 짧아지게 됨.

C값이 아무리 커지거나 작아져도 결정경계선은 하나만 산출됨
but Gamma 값은 커질수록 각각의 관측치에 대한 결정경계선 범위가 작아지기 때문에 여러 개의 결정경계선이 생길 수 있음.

+실습
13-9. 연관규칙과 협업 필터링(추천 모델)


Tailored to individual users 방식:
- 제품이나 컨텐츠 소비에는 연관관계가 존재하고, 이를 수학적으로 도출하여 특정 시점에 특정 고객이 관심 가질 만한 제품이나 컨텐츠를 찾아 주는 것이 추천시스템
- 추천 시스템은 크게 연관 규칙, 협업 필터링, 컨텐츠 기반 필터링으로 나눌 수 있음
< 연관 규칙 >
연관규칙 분석 : 제품 A를 구매한 사람은 제품 B를 구매할 확률이 높다는 결과를 이끌어 내는 모델.
과거 고객들의 구매이력을 통해 추천 점수를 구하며 대표적인 연관규칙 분석의 알고리즘으로는 Apriori, FP - Growth, DHP 알고리즘 등이 있음.


아이템 A를 구매한 사람이 아이템 B를 구매할 것인지 분석한다고 했을 때, A를 구매한 현상은 조건 절이 되고 (A를 구매했을 때) B를 구매하는 현상은 결과 절이 된다(이는 (A → B)로 표현할 수 있다). 연관규칙 분석에서는 다음 세 가지 지표를 통해 품목 조합 간 연관성의 수준을 도출한다.

<지지도>
전체 구매 횟수 중에서 조합의 구매가 얼마나 발생하는지 나타내기 때문에 다음과 같이 표현된다.


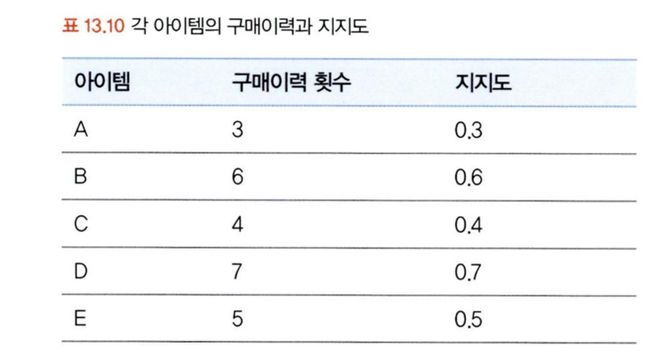

→ 이런 식으로 3개, 4개… 조합의 양을 늘려 가며 모든 조합의 지지도를 구할 수 있지만 계산량이 기하급수적으로 늘어나게 된다. 이를 해결하기 위한 방법이 Apriori 알고리즘이다.
<신뢰도>
아이템 A가 판매되었을 때 아이템 B가 판매될 조건부 확률을 의미하며 수식으로는 다음과 같이 표현된다.



아이템 A에 대한 지지도는 0.3이고 아이템 B가 함께 팔리는 경우에 지지도는 0.2이다. 신뢰도 P(A → B)는 A가 팔릴 때 B도 같이 팔리는 비율이므로 0.2를 0.3으로 나눈 값인 0.67이 된다. 이때 조건절의 지지도는 결과절의 지지도보다 항상 크기 때문에 신뢰도는 1보다 클 수 없다 ( P(A → B)와 P(B → A)는 다를 수 있으며 이러한 척도를 비대칭적 척도라고 한다 ).
<향상도>
향상도(Lift)는 A의 판매 중 B가 포함된 비율이, 전체 거래 중 B가 판매된 비율보다 얼마나 증가했는지를 나타낸다. 이는 A와 B의 신뢰도를 B의 지지도로 나눠준 것이며 두 아이템 간의 연관성을 나타내는 지표이기 때문에 조건절과 결과절의 위치가 바뀌어도 값은 동일하다. 이러한 척도를 대칭적 척도라고 한다. 향상도를 벤다이어그램으로 표현하면 다음과 같다.

향상도가 1에 가까울수록 두 아이템은 서로 독립적인 관계이며 1보다 작으면 음의 상관관계(A를 구매하는 사람은 B를 구매하지 않는 경향이 있다)를 가지고, 1보다 크면 A를 구매한 사람이 B도 구매하는 경향이 강하다는 결과를 나타낸다. 위 예시에서 아이템 조합별로 향상도를 구해 보면 다음과 같다.

세 개의 기준 척도를 이용해 상품을 추천해 주어야 한다. 우선 지지도와 신뢰도가 특정 수치 이하인 관계는 필터링해 제거해 준다. A와 B의 향상도가 아무리 높더라도 거래가 거의 이루어지지 않는 아이템이라면 비즈니스적으로 효과가 적기 때문이다.
→ 이후 향상도 순서로 정렬하여 향상도가 높은 아이템 조합을 선정한다. 이때 추천 시스템이 매출에 얼마나 효과적일지도 고려해야 하기 때문에 지지도를 함께 보는 것이 좋으며 특정 아이템을 지정하여 추천 상품을 찾을 때는 해당 아이템을 포함한 조합들을 필터링하여 지표를 확인하면 된다.
→ 연관규칙 분석에는 고려할 지표가 세 가지나 되기 때문에 분석가의 주관이 들어가기 쉽다. 따라서 이를 보완한 평가 척도가 존재하며 대표적으로는 IS 척도와 교차지지도(Cross support)가 있다.
< IS 척도 >
향상도와 지지도를 곱한 뒤 제곱근을 취한 값이며 향상도와 지지도 중 하나가 너무 낮음에도 연관규칙으로 선택되는 문제를 방지할 수 있다. 향상도와 지지도 중에 비중을 더 주고 싶은 지표가 있을 때는 가중치를 줄 수 있다. 공식으로 표현하면 다음과 같다.

< 교차지지도(Cross support) >
차지지도는 전체 아이템 조합에서 얼마 이하의 지지도를 가진 아이템 조합을 버릴 것인지를 판단하는 보조지표이다. 이는 전체 아이템 중에서 최대 지지도를 가진 아이템 대비 최소 지지도가 어느정도 차이를 보이는지 나타내며 이를 기반으로 지지도 기준을 잡을 수 있다. 교차지지도 수치가 낮을수록 지지도의 차이가 크다는 것을 의미하며 의미 없는 아이템 조합이 포함되었을 가능성이 높음을 나타낸다.

연관 분석에서는 모든 조합에 대한 지지도, 신뢰도, 향상도를 계산해야 하기 때문에 아이템 품목이 늘어날수록 계산량이 매우 늘어난다. 아이템이 n개일 때 최대 2^(n) - 1개의 조합에 대해 연산을 해야 하며 아이템이 하나씩 늘어날수록 연산량은 지수적으로 늘어나게 된다.
-> 이를 해결하기 위해 Apriori 알고리즘은 지지도와 신뢰도 제한 방식을 사용해 지지도나 신뢰도가 낮은 조합은 애초에 연산 대상에서 제외한다. 밑 그림에서처럼 5개의 아이템, 31개의 조합이 존재할 때(이런 식으로 조합을 계산하는 과정을 self - join)이라고 한다) 지지도가 일정 수치 이하인 조합과 해당 조합이 포함된 조합은 모두 pluning을 하여 연산 대상에서 제외한다. 밑 그림에서는 AB 조합이 포함된 모든 조합이 pluning된 것을 확인할 수 있다.


< 컨텐츠 기반 필터링과 협업 필터링 >
컨텐츠 기반 필터링은 아이템의 속성을 데이터화하여 고객이 선호하거나 구매한 제품과 유사한 속성을 가진 제품을 추천한다. 하지만 모든 아이템에 대한 메타 정보를 입력해야 하기 때문에 아이템이 많아질 경우 관리가 힘들어지며 구매자가 선호를 표현한 제품과 속성이 유사하지 않더라도 구매할 가능성이 높은 제품을 추천하지 못한다는 단점이 있다.
이때 위 두 가지 단점을 해결할 수 있는 모델이 협업 필터링 모델이다. 협업 필터링 모델은 다시 최근접 이웃 모델과 잠재요인 모델로 구분될 수 있다. 또한 최근접 이웃 방식은 다시 사용자 기반과 아이템 기반 방식으로 구분된다.
최근접 이웃 모델은 사용자가 아이템에 매긴 평점 데이터를 기반으로 다른 아이템들에 대한 평점을 예측하고, 예측 평점이 높은 아이템들을 추천해주는 방식이다. 사용자 A~E의 5개의 영화에 대한 평점 데이터를 예시로 들어보면 다음과 같다.
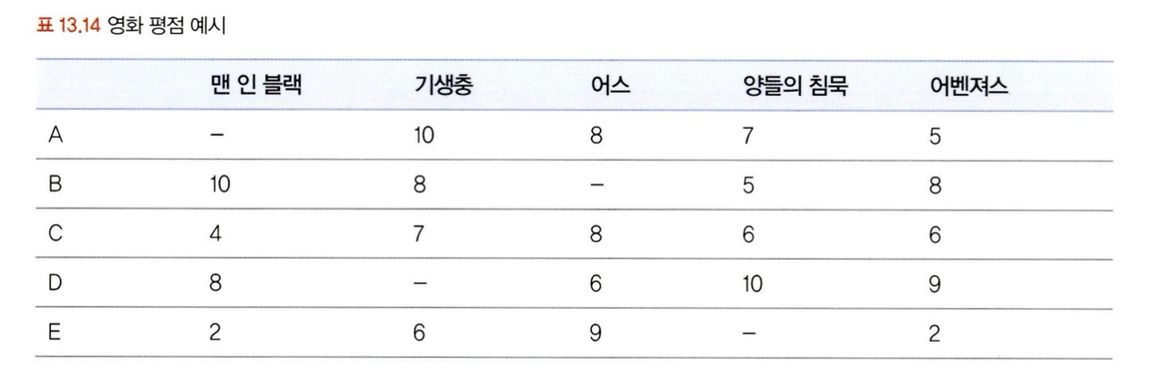
→ 우선 사용자 기반의 협업 필터링 모델은 피어슨 유사도나 코사인 유사도를 통해 유사한 성향을 가진 사람들을 찾아내어 그 사람들이 선호하는 아이템을 추천해 주는 방식이다. 사용자 A~E의 서로 간 피어슨 유사도를 구하면 다음과 같다.
사용자가 보지 않았던 영화의 평점을 예측할 때, 유사도가 높은 사람의 점수는 강하게, 유사도가 낮은 사람의 점수는 약하게 반영해 유사도를 반영할 수 있다. 예측 평점을 구하는 공식은 다음과 같다.
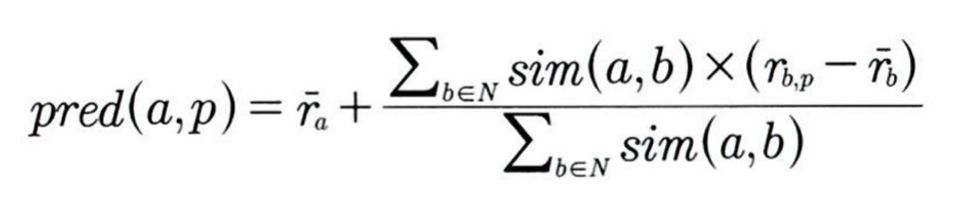
이를 해석해보면, 다른 사람이 영화에 준 평점에서 다른 모든 사람들의 해당 영화 평점 평균을 빼고, 그 사람과의 유사도를 곱한 값들을 모든 다른 사람에 대해 구해서 더하면 예측 평점을 구할 수 있다.
→ 아이템 기반의 최근접 이웃 모델은 사용자 기반 모델에서 관점을 아이템으로 바꾸면 된다. 이때는 아이템 간의 유사도를 통해 한 아이템을 구매했을 때 유사도가 높은 순으로 다른 아이템을 추천해 줄 수 있다.
상품 추천에도 협업 필터링 모델을 사용할 수 있다. 하지만 구매자들이 제품에 평점을 주는 경우가 많지 않으므로(이러한 문제를 희소 행렬이라 한다) 이때는 고객들의 구매 이력, 클릭, 장바구니 담기 등의 데이터를 활용한다.
→ 영화평점과 같이 호불호가 명확한 데이터를 명시적 데이터라고 하고 구매, 클릭과 같은 데이터를 암묵적 데이터라 한다. 암묵적 데이터에서는 사용자의 호불호를 알 수 없는데, 한번 구매한 제품보다 세번 구매한 제품을 더 선호하는지 알 수 없으며 클릭하지 않은 제품이 보지 못해서인지 선호하지 않아서인지 알 수 없다.
→ 암묵적 데이터 위주의 도메인에서는 협업 필터링 중 잠재요인 모델을 사용할 수 있다. 잠재요인 모델은 사용자와 아이템 간의 관계 정보를 가지는 데이터를 행렬분해하여 잠재 요인을 도출하며 일반적으로는 20~100가지의 잠재 요인을 만든다. 대규모의 다차원 행렬에 차원감소 기법을 사용하여 잠재요인을 추출해내며 이는 주성분 분석과 비슷한 개념이다.
→ 우선 위와 같은 방법으로 사용자 - 아이템 데이터 행렬을 사용자 - 잠재요인, 아이템 - 잠재요인 행렬로 분해한다. 이를 통해 사용자와 아이템 각각의 속성을 추출할 수 있으며 이를 통해 서로 비슷한 속성을 가진 사용자(아이템)들을 선별할 수 있다. 행렬을 분해하는 기본적인 기법으로는 특잇값 분해(SVD)가 있는데, 이는 데이터가 null값으로 누락된 경우 이를 모두 평균값 등으로 대치시켜줘야 하고, 아이템이 많아 희소 행렬인 경우 데이터가 왜곡될 가능성이 크다.
→ 관측된 데이터만으로 행렬분해를 할 수 있어 일반적으로 사용되는 알고리즘으로는 ALS와 SGD가 있다. 두 알고리즘은 유사하지만 ALS는 병렬 시스템을 지원하기 때문에 대량의 데이터를 처리할 때 유리하다는 차이점이 있다. 이를 통해 분해한 행렬을 다시 내적하여 하나의 행렬로 만들면 기존에 가졌던 값들과 유사한 수치가 나오게 되며(잠재요소는 기존 값의 속성을 가지고 있기 때문이다) 비어 있던 값들도 채워지게 된다(모든 사용자와 모든 아이템의 잠재요인을 곱해 사용자의 관심을 수치화하기 때문이다).
협업 필터링에도 문제점이 있다. 우선 콜드 스타트 문제가 있는데, 새로 가입한 사용자나 새로 출시된 아이템의 경우 상호작용 데이터가 없어 추천을 위한 점수를 줄 수가 없다. 이 경우는 사용자가 가입할 때 선호하는 아이템을 몇 가지 선택하도록 하거나 신규 아이템의 잠재요인을 특성이 유사한 아이템들의 잠재요인 평균으로 대치하여 해결할 수 있고 Simple aggregates를 통해 별도의 신제품 추천 리스트를 제공할 수도 있다.
→ 또한 아이템 수에 비해 구매, 클릭 등의 상호작용이 부족하여 추천 성능이 떨어지는 문제점이 발생하는 경우에는 하이브리드 필터링 모델을 사용한다. 하지만 이는 행동 양식이 일관적이지 않은 특이 취향 사용자에 대한 추천 정확도가 떨어지기 때문에 특이 취향 사용자는 분리해 내어 별도의 유사도 알고리즘을 적용해야 한다.
<하이브리드 필터링 세 종류>

→ 1번의 방식은 컨텐츠 기반 필터링과 협업 필터링을 각각 구현한 뒤 각 모델의 결괏값에 가중치를 곱해 통합하여 최종 스코어를 산출한다. 혹은 가중합을 구하지 않고 더 나은 결괏값을 가지는 모델을 선택하여 사용할 수 있는데 처음 가입한 사용자에게는 컨텐츠 기반 필터링으로 아이템을 추천해 주다가 상호작용 데이터가 어느 정도 쌓인 뒤에는 협업 필터링 모델로 전환해 주는 식으로 활용할 수 있다.
→ 2번의 방식은 협업 필터링 모델에 사용자의 특성을 나타내는 변수를 추가햐여 희소 행렬의 문제를 완화한다. 신규 아이템의 잠재요인을 유사한 아이템들의 잠재요인 평균으로 대치하는 방법도 이에 해당된다.
→ 3번의 방법은 사용자의 성별, 연령, 취향 등의 정보들을 협업 필터링 방식에서처럼 차원 압축하여 몇 개의 잠재요인으로 변환하여 사용하는 방식이다. 이를 통해 유의미한 속성 정보를 추려낼 수 있고 데이터양을 감소시켜 효율을 높일 수 있다.
'데이터 분석가가 반드시 알아야할 모든 것' 카테고리의 다른 글
| 모델 평가 (0) | 2024.04.10 |
|---|---|
| 데이터 분석하기2 (1) | 2024.04.03 |
| 데이터 분석하기 (0) | 2024.03.27 |
| 데이터 전처리와 파생변수 생성 (0) | 2024.03.20 |
| 데이터 탐색과 시각화 (0) | 2024.03.13 |