14-1. 학습 셋, 검증 셋, 테스트 셋과 과적합 해결
학습 셋과 테스트 셋을 나누고, 학습 셋의 일부의 검증 셋(7:3)으로 분리


Degree 1 : 모델이 너무 단순해서 Y값을 제대로 예측하지 못함, 학습이 너무 덜 된 경우 과소적합(underfitting)
Degree 15 : 학습 셋에 과도하게 적합(fit)하도록 학습된 과적합 상태(overfitting)
-> 학습이 너무 많이 이루어지거나, 변수가 너무 복잡해서 발생, train 데이터와 test 데이터가 중복될 경우 발생
Degree 5 : 최적의 모델 True function과 가장 유사한 모델
검증셋 : 학습 셋 데이터를 통해 모델을 만들 때 과도하게 학습되지 않도록 조정해주는 역할을 함


-> 검증 셋 데이터는 학습 셋 데이터의 모델 학습 과정에 관여하여 모델의 과적합을 방지해 주는 역할을 함
테스트 셋 : 학습 셋과 검증 셋으로 만든 최종 모델의 실제 '최종 성능'을 평가할 때 사용
-> 검증 셋도 결국 모델을 만들 때 관여한 데이터기 때문에 모델 성능 지표가 다소 과장되어 있기 때문에 모델 산출시 사용되지 않았던 테스트 셋 데이터를 통해 실제적인 모델의 정확도를 판단.
레이블 : 종속변수, 즉 정답지 Y
홀드아웃(holdout) : 과적합을 방지하는 가장 기본적인 테스트셋 분리 방법
-> 정답지가 있는 학습 셋과 검증 셋 데이터로 모델을 만들고, 모델을 테스트 셋 데이터에 적용하여 산출한 예측값을 테스트 셋 레이블과 비교하여 모델 성능 평가
반복 학습을 많이 하지 않는 간단한 모델에는 검증 셋 사용을 생략하고 바로 테스트 셋에 모델을 적용하여 과적합을 검증함
BUT 반복 횟수가 100회 이상으로 많은 모델을 만들 때에는 model.fit(..., validation_data = (x_test, y_test)) 과 같이 검증 셋을 설정해줌!

정규화(Regularization) : 모델 내부의 계수인 세타( θ ) 값에 패널티를 주어 변수의 영향력을 감소시키는 기법
-> 과적합된 모델의 각 가중치를 줄여 줌으로써 예측이 불필요한 변수의 영향을 최소화함
드롭아웃(dropout) : 주로 신경망 모델에서 사용되며, 최종 결괏값을 계산하기 위해서 사용되는 뉴런들 중 일부를 누락(dropout)시켜 과적합을 방지하는 기법
-> 은닉층에 드롭 아웃 확률 p를 설정하면, p의 확률로 은닉층의 뉴런들이 제외됨
-> 일부 뉴런이 제거된 여러 개의 모델의 결괏값을 앙상블 하기 때문에 예측 성능이 향상됨
-> 일종의 앙상블 학습 기법

14-2. 주요 교차 검증 방법
홀드아웃은 결국 전체 중 일부인 검증 셋의 데이터로만 적정 학습 수준을 결정한 모델이기 때문에 과적합을 완전히 방지했다고 할 수 없음 ( 학습 데이터가 충분히 많지 않다면)
<k-Fold Cross Validation>
한정된 데이터를 가지고 최대한 과적합을 방지하여 모델을 학습시킬 수 있는 방법 중 하나
k-fold 교차 검증 (k - Fold Cross Validation) : 전체 학습 데이터 중 일부를 검증 셋으로 분리하는 과정을 k번 반복하는 방법

1. 전체 학습 셋을 k 개의 조각(fold)으로 분리
2. 검증 셋을 중복 없이 바꿔가면서 모델 생성과 평가 진행
3. 만들어진 k개의 모델의 모든분할 조합의 평균 계숫값을 구하거나 최고 성능의 모델을 선택
4. 테스트 셋을 통해 최종 예측력을 평가
일반적으로 k의 수는 5~10개로 지정하여 수행
- k가 클수록 평가의 편중된 정도(bias)는 낮아지지만, 각 fold의 모델별 결과의 분산(variance)이 높을 수 있으므로 K가 크다고 무조건 좋은 것은 아님!
-) 홀드아웃 방식보다 연산량이 많음
<LOOCV(Leave-one-out Cross-validation)>
LOOCV(Leave-one-out Cross-validation) : 기존 k-fold 방식에서 k를 최대화한 방법으로 k를 전체 관측치 수로 하여, 검증 셋이 관측치 하나 하나가 되는 것
- 전체 관측치가 1000개인 데이터 셋이면 k가 1000인 k-fold 교차검증을 수행함
-) 모델의 편중이 매우 작지만 결괏값의 분산이 다소 커 과적합 될 여지가 있음
-> 데이터양이 많은 경우에는 적합하지 않은 방법

<Stratified K-fold Cross Validation>
Stratified K-fold Cross Validation(Stratified K-fold 교차검증) : 기존 k-fold 방식에 층화 추출 방식을 접목한 기법
-> 데이터의 특정 클래스(카테고리)가 한 곳에 몰리는 상황을 방지할 수 있음
-> 클래스 분포가 일정하지 않으면 각 분할 셋 간 계숫값의 분산이 커지게 됨
-> 분할 셋 안의 클래스 비율이 학습 셋 전체의 클래스 비율과 같도록 분리

<Nested Cross Validation>
기존 k-fold 방식 : 학습 셋과 테스트 셋 분리를 한 번만 하기 때문에, 모델의 성능이 테스트 셋에 크게 의존한다는 문제 있음
중첩 교차검증(Nested CV) : 학습 셋과 테스트 셋 검증에도 k-fold 방식을 적용한 것
-> k-fold를 이중으로 중첩하여 사용하므로 inner loop와 outer loop로 구성됨

Inner loop : 기존의 k-fold 교차검증과 마찬가지로 학습 셋과 분류된 데이터를 k-1 개의 테스트셋과 1개의 검증 셋으로 나누어 k 번 학습을 수행하여 계숫값을 산출함
outer loop : inner loop에서 만들어진 계숫값을 테스트 셋에 적용하여 정확도를 산출하는 작업을 k-fold 방식으로 수행함
-> 전체 데이터를 테스트 셋 데이터로 활용하기 때문에, 만든 모델이 얼마나 잘 일반화되는지 평가하는 데 유용함
-> 모델의 최종 예측력은 각 fold의 예측력 평균으로 구함
<Grid Search Cross Validation>
격자 탐색 교차검증: 모델의 하이퍼 파라미터 값을 리스트 형태로 미리 입력해 놓은 다음 각 조건의 모델 성능을 측정하고 평가하여 효율적으로 최적의 하이퍼 파라미터 값을 찾아내는 기법
- sklearn의 GridSearchCV 패키지로 제공됨
- 각 조건의 모델을 교차검증으로 평가하여 최적의 모델 조건을 찾는 것

그리드 방식 : 사전에 설정한 모든 허이퍼 파라미터 조건의 모델을 수행하기 때문에 조건이 많아지면 시간이 오래걸림
-> 조건이 많은 경우레는 현실적으로 가능한 횟수(1000회 등) 내에서 무작위로 조건을 탐색하여 최적의 조건을 찾는 무작위 탐색(randomized search) 방법을 사용하기도 함
<주요 교차 검증 방법 실습>
14-3. 회귀성능 평가지표
회귀 모델의 성능(정확도)을 평가하는 주요 방법들
<R-Square와 Adjusted R-Square>
결정계수(R-Square(R^2) : 모델의 독립변수들이 종속변수를 설명할 수 있는 설명력을 나타내는 0에서 1 사이의 수치
-> 회귀모델의 회귀선이 종속변수 y값을 얼마나 잘 설명할 수 있는가를 의미
-> 실젯값과 예측값의 차이인 오차와, 실젯값과 실젯값 평균의 차이인 편차와 관련 있음

SSR(Sum of square regression) : 회귀식의 추정값과 전체 실젯값 평균과의 편차 제곱합
SSE(Explained sum of squares) : 회귀식의 추정값과 실젯값 편차 제곱의 합
SST(Total sum of squares) : 실젯값과 전체 실젯값 평균과의 편차 제곱합

-> R-Square 의 값은 SSR 값이 클수록(회귀선이 각 데이터를 고르게 설명한다는 의미), SST 값이 작을수록(SSR을 제외한 SSE가 작다는 의미) 커짐
Adjusted R-Square : R-Square가 독립 변수의 개수가 많아질수록 값이 커지는 문제를 보정한 기준
-> SSE 와 SST를 각각의 자유도로 나누어 구함

<RMSE(Root Mean Square Error)>
회귀모델은 수치를 정확히 맞춘 비율이 아닌, 실제 수치와의 차이를 평가 지표로 사용
RMSE : 편차 제곱의 평균에 루트를 씌운 값으로, 실제 수치와 예측한 수치와의 차이를 확인하는 전형적인 방법
-> 예측값에서 실젯값을 뺀 후 제곱한 값을 모두 더한 다음, n으로 나누고 루트를 씌움(실젯값과 예측값의 표준편차)

+) 표본 평균과의 비교를 통해 대략적인 모델 간 정확도 비교 가능
-) 예측값의 스케일에 영향을 받음 -> 표본 데이터가 다르면 RMSE 절대치로 비교 불가능
<MAE(Mean Absolute Error>
MAE : 실젯값과 예측값의 차이 절댓값 합을 n으로 나눈 값
-> 직관적으로 예측값 차이 비교 가능

RMSE: 평균 제곱 오차
-> 오차값을 제곱하기 때문에 이상치에 더 민감함
-> 실젯값과 예측값의 오차가 들쑥날쑥하지 않은 모델을 더 우수하게 평가
MAE: 평균 절대 오차
-> 절대 오차 합이 더 적은 모델을 더 우수하게 평가
<MAPE(Mean Absolute Percentage Erorr>
MAPE : 백분율 오차, MAE를 퍼센트로 변환한 것
-> 스케일에 관계없이 절대적인 차이를 비교할 수 있으므로 다른 데이터가 들어간 모델 간 성능을 비교하기에 유용
-> 0부터 무한대의 값을 가질 수 있으며, 0에 가까울수록 우수한 모델

1. 실젯값이 0인 경우에는 0으로 나눌 수 없기에 분석 소프트웨어는 알아서 실젯값이 0인 관측치를 제외하고 계산
-> 실젯값에 0이 많은 데이터는 MAPE 평가 기준을 사용하는 것이 적합하지 않음
2. 실젯값이 양수인 경우, 실젯값보다 작은 값으로 예측했을 때 MAPE의 최댓값이 최대 100%까지만 커질 수 있으나 실젯값보다 큰 값으로 예측했을 때는 MAPE 값에 한계가 존재하지 않음
-> 따라서 실젯값보다 작은 값으로 예측하도록 편향될 수 있음
3. 실젯값이 0과 매우 가까운 경우에 MAPE가 과도하게 높아질 수 있음
-> 성능평가 방법을 선정하기 전에 실젯값과 예측값의 분포를 확인하고 이러한 주의점들을 고려하여 적합한 방법을 선택해야 함.
<RMSLE(Root Mean Square Logarithmic Error)>
RMSLE: RMSE와 동일한 수식에서 실젯값과 예측값에 1을 더하고 로그를 취해준 값이며 로그를취해 주었기 때문에 상대적 비율을 비교할 수 있음
-> RMSE보다 이상치에 덜 민감하기 때문에 실젯값에 이상치가 존재하는 경우에 적절한 방식
-> 로그를 취하기 전에 1을 더해주는 이유는 실젯값이 0일 때 log(0)이 무한대로 발산하기 때문

- 스케일이 차이가 나더라도 비율 오차(실젯값에 대한 오차의 비율)가 같으면 동일한 RMSLE 값을 산출
- 로그의 특성상 실젯값보다 크게 예측하는 경우보다 작게 예측하는 경우에 더 큰 페널티를 주기 때문에 상품 수요 예측에 유용 -> 일반적으로 수요를 높게 예측해 재고비용이 생기는 것보다 수요를 낮게 예측해 기회 손실이 발생하는 경우가 타격이 크기 때문
< AIC와 BIC >
AIC(아카이케 정보 기준) : 최대 우도(Likelihood, 모델이 데이터를 설명하는 적합도)에 독립변수가 얼마나 많은가에 따른 페널티를 반영하는 평가 척도
- 독립변수가 많아지면 차원의 저주에 의해 모델 성능이 떨어질 수 있기에 모델의 정확도와 함께 독립변수가 많고 적음까지 따지는 평가 방법
AIC 값이 작을수록 좋은 모델이며, 우도가 높을수록, 변수가 적을수록 AIC값은 작아짐.
-> 변수가 늘어날수록 모델의 편의(bias)는 감소하지만 분산(variance)은 증가하며, AIC는 적절한 변수의 개수를 찾는 데에 유용한 평가 방법!

2log(Liklihood) : 모델의 적합도
k : 상수항을 포함한 독립변수의 개수
-> 독립변수의 수가 증가할수록 AIC값 높아짐


AIC에서는 데이터 수에 대한 보정이 없기 때문에 관측치가 많지 않을 경우 정확도가 낮아질 수 있음
-> 관측치 수를 반영하여 보정된 AICc 방식을 사용할 수 있으며 이 또한 작은 값을 가질수록 좋은 모델을 나타냄.
BIC: AIC와 변수 개수에 대한 페널티에서 차이가 있음

BIC에서는 관측치가 8개 이상만 되어도 AIC보다 변수 개수에 대한 패널티를 더 크게 부여하기 때문에, 변수의 개수를 줄이는 것이 중요한 상황에서는 BIC로 모델을 평가하는 것이 좋음!
< 회귀성능 평가지표 실습>
14-4. 분류, 추천 성능 평가지표
분류 모델에도 다양한 모델 평가 방법이 존재
-> 예측한 전체 관측치 중 몇 개를 정확히 분류했는가를 주로 평가
< 혼동 행렬 >
1. 테스트 셋의 모든 관측치의 구매 여부 1과 0에 대한 확률을 구함.
2. 분류 기준값(threshold)에 맞춰(일반적으로 0.5) 1의 확률이 0.5 이상인 관측치는 1로 분류하고 나머지는 0으로 분류

혼동행렬의 기본 틀
오분류율 : 제대로 관측하지 못한 관측치의 수를 전체 관측치의 수로 나눠 구함
1로 예측했는데 실제로도 1인 경우를 진양성(True Positive), 실제로는 0인 경우를 위양성(False Positive), 0으로 예측했는데 실제로도 0인 경우는 진음성(True Negative), 실제로는 1인 경우를 위음성(False Negative)이라고 한함.
-> Positive와 Negative는 긍정과 부정의 의미보다 분류하고자 하는 1값과 0값, 즉 구매여부의 구매, 탈퇴 여부의 탈퇴, 질병 양성 여부의 양성 등을 의미


< 정확도, 오분류율, 정밀도, 민감도 특이도 그리고 f - score >
정확도 : 전체 관측치 중에서 올바르게(1은 1로, 0은 0으로) 분류한 비중
오분류율(Misclassification rate) : 전체 관측치 중에서 잘못 분류한 비중
-> 정확도 + 오분류율 = 1


정밀도 : 1로 예측한 관측치 중 실제로 1인 관측치 비중. 모델이 실제 1을 제대로 분류하는 성능을 확인할 때 사용

정확도와 정밀도 평가 시 주의해야 하는 부분
- 대부분의 데이터셋은 실젯값이 1인 관측치의 비중이 적으며, 오버샘플링이나 언더샘플링을 적용하지 않고 모델 생성 및 예측을 하기도 함. 이때 0과 1의 실젯값 비율이 8:2라고 가정하는 경우, 모두 극단적으로 0으로 분류하도록 모델을 만들더라도 정확도는 80%가 됨. 이러한 현상을 정확성 역설이라고 함.
- 모델이 단 하나의 관측치만 1로 예측했고, 실젯값도 1인 경우 그 모델의 정밀도는 100%가 됨.
- > 정확도와 정밀도만으로 모델의 성능을 평가하는 것은 위험하며 다른 평가 기준들을 종합해서 모델 성능을 평가 필요
민감도(재현율) : 실제 1인 관측치 중 모델이 1로 분류한 비중일반적으로는 50% 이상의 민감도를 유지하도록 함.
특이도: 0으로 분류한 관측치 중 실젯값도 0인 비중을 나타냄. 보통 전체 관측치에서 1보다 0이 많은 비중을 차지하기 때문에 특이도 값은 높게 나오며, 가끔 1과 0의 비중이 비슷하거나 0에 대한 분류가 중요할 때 특이도를 확인함.

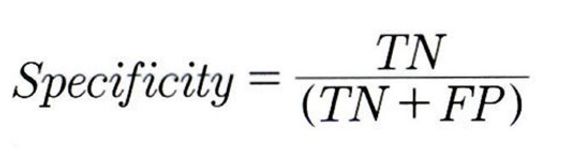
F - score : 정밀도와 민감도를 함께 고려한 것으로, 0~1 사이의 값을 갖음.
정밀도와 민감도는 서로 트레이드오프 관계로, 둘중 하나가 증가하면 나머지 하나는 감소
-> 정밀도를 높인다는 것은 1일 것이 거의 확실한 관측치만 1로 분류한다는 의미이므로 1 전체 중에 1로 분류되는 비중인 민감도는 감소
-> 정밀도와 민감도의 조화평균을 기준값으로 사용하며, 조화평균이 상대적으로 작은 값 위주로 평균을 구하기 때문에 정밀도와 민감도가 한쪽으로 치우치지 않았을 때 F - score는 높은 값을 갖게 됨
->모델 성능을 평가할 때는 정밀도와 민감도, F - score를 종합적으로 판단하는 것이 좋음

베타 제곱은 조화평균의 가중치로, 베타 값이 1 미만일 때 정밀도가 중요시되고 베타 값이 1을 초과할 때는 민감도를 중요시하게 됨.
베타 값이 1일 때는 정밀도와 민감도를 동일하게 중요시하며 이를 F1 - score라고 하고 이는 가장 많이 쓰이는 F - score 기준값!
F - score와 유사한 개념으로 G - mean이 있음
G - mean : 기하평균을 사용해 민감도와 특이도의 평균을 구하는데, 이는 실제 1을 제대로 분류한 비율과 실제 0을 제대로 분류한 비율의 기하평균
-> 기하평균에서는 더 작은 값에 가중치를 주기 때문에 민감도와 특이도 중 하나의 값이 확연히 떨어지면 G - mean 값은 단순 산술평균 값보다 낮아지게 됨.

< 향상도 테이블과 향상도 차트, 그리고 향상도 곡선 >
향상도(Lift) : 전체 관측치 중에서 실제 1의 비율보다 모델을 통해 1로 예측한 관측치 중 1의 비율이 얼마나 더 높은지를 나타냄
정확도, 오분류율, 정밀도 등은 분류 임계치인 threshold 값에 따라 변화
-> 이때 향상도 테이블과 향상도 곡선을 통해 threshold 값에 대한 모델을 평가할 수 있으며 적정한 threshold값을 선정할 수도 있음

향상도 테이블에서는 모델에서 1로 분류할 확률이 높은 관측치는 실제로 1인 경우가 많다는 것을 전제로 함.
-> 모델이 제대로 학습되어 관측치가 1로 분류될 확률이 높을수록 실젯값이 1일 확률이 높아야 함!
-> 무작위로 1을 뽑는 확률보다 모델이 1을 분류할 확률이 낮으면 향상도는 1 미만이 됨
향상도 테이블을 만드는 과정


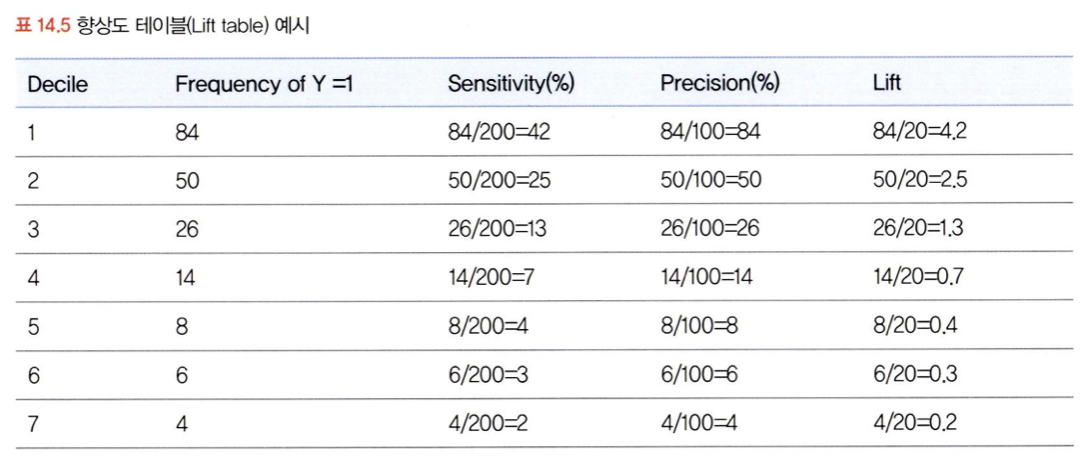

상위분위 수에 1이 더 많이 포함될수록 1을 더 잘맞춤
분위수가 바뀔 때마다 향상도 값이 확연히 줄어드는 형태가 이상적이며, 이를 향상도 차트 = 십분위도로 확인 가능


향상도 차트를 누적 형태로 변환하면 임곗값 threshold를 정할 때 사용할 수 있음 (1~3분위수동안 향상도 값 변화를 보고 임곗값을 정함)
- 그래프 길이 격차가 커지는 지점을 선택
- 보통 100분위 수로 나눈 누적 향상도 곡선을 사용(차트 : 10분위수)


< ROC곡선과 AUC >
- 객관적으로 모델 비교 및 평가 가능
- 임곗값 threshold를 결정하는 데 유용
1-특이도 : 전체 실제 '0'값 중 1로 잘못 분류된 비율
Roc 곡선 : 민감도와 1-특이도 값의 변화를 그래프로 그려 분류 모델의 성능 평가

- 분류 성능이 우수한 모델은 ROC 곡선이 좌측 상단으로 볼록한 형태
AUC : ROC 곡선을 수치로 계산하는 것으로 곡선아래 면적의 크기를 구함.
1: 우수한 모델
0.5: 랜덤 분류
0.5이하: 데이터에 이상이 있음.


< 수익곡선 >
수익곡선: 진양성에 따른 이익과 위양성에 따른 손해를 수치화하여 모델의 수익성을 최대화 할때 사용하는 것
- 가용 예산 안에서 최대의 수익을 얻을 수 있는 지점을 선택
2번이 최적의 수익을 낼 수 있는 모델
-> 고객 구간이 넓어질수록 가정한 예상 비용에 대한 오차가 커지므로 주의

< Precision at k, Recall at K, MAP >

-> k 를 하나씩 늘려가며 precision과 recall 의 수치를 비교함




MAP : 사용자들이 반응했던 항목 구간들의 precision 들을 모두 평균을 낸 모델 평가 척도


14-5. A/B 테스트와 MAB
< A/B 테스트 >
- as-is 와 to-be의 결과를 직접 비교
- 임의로 두 집단으로 나누어 서로 다른 콘텐츠를 보여 준 다음 어떤 집단이 더 높은 성과를 보이는지를 비교


-> A/B 테스트를 통해 시안 B가 더 우수한 배너로 채택


- 고객 반응을 지속적으로 모니터링해야함!
- 표본 그룹이 편향되지 않도록 무작위 추출이 시행되어야 함!
- 추출 방법에 유의해야 함!
- 충분한 표본을 확보해야함!
- 지속적으로 진행되어야 함!
-) 최적의 조건을 찾을 때 까지 오랜 시간과 비용이 필요하며 기회 비용이 크고 빠른 트랜드 변화에 민감
-> MAB
< MAB 테스트 >
MAB 테스트 :강화학습의 기초 개념

MAB 의 목적은 조합을 최적화하여 최대의 이익을 얻는 것으로 최적의 수익을 내기 위한 전략

'데이터 분석가가 반드시 알아야할 모든 것' 카테고리의 다른 글
| 서포트벡터머신, 연관규칙과 협업 필터링 (0) | 2024.05.01 |
|---|---|
| 데이터 분석하기2 (1) | 2024.04.03 |
| 데이터 분석하기 (0) | 2024.03.27 |
| 데이터 전처리와 파생변수 생성 (0) | 2024.03.20 |
| 데이터 탐색과 시각화 (0) | 2024.03.13 |