13-3. 의사결정나무와 랜덤포레스트(예측/분류 모델)
의사결정나무(decision tree) 분석 기법 : 나뭇가지들이 뻗어 있는 형태로 데이터들이 분리되어 가며 최적의 예측 조건을 만드는 것 ( 가지가 나눠지는 부분은 독립변수의 조건, 마지막 잎사귀들은 최종의 종속변숫값)
- 분류나무(Classification tree) : 명목형 종속변수를 분류할 수 있음, 양적 척도와 질적 척도의 독립변수 다 사용 가능
- 회귀나무(Regression tree) : 연속형의 수를 예측할 수 있음, 양적 척도와 질적 척도의 독립변수 다 사용 가능
<분류나무>

뿌리 노드(Root Node) : 분류가 시작되는 전체 데이터 노드(1)
부모 노드(Parent Node) : 분리되기 전의 노드(1은 2,3의 부모 노드)
자식 노드(Child Node) : 분리된 후의 노드(2와 3은 1의 자식 노드)
중간 노드(internal Node) : 나무 구조 중간에 있는 노드(3)
끝 노드(Terminal Node, Leaf) : 더 이상 분리되지 않는 끝 노드(2,4,5)
깊이(Depth) : 뿌리 노드부터 끝 노드까지 노드의 층수(총 3의 깊이)
-> 기본적으로 데이터를 얼마나 잘 분류했는지 알 수 있는 척도인 불순도(Impurity)를 낮추고 순도(Homogeneity)를 높이는 방향으로 분류 기준을 찾아냄!
-> 한 노드 내에서는 범주의 동질성 높게, 노드 간에는 이질성이 높게 독립변수와 분류 기준값을 채택
<데이터의 불순도를 나타내는 대표적인 기준>
- 지니 계수(Gini index) :1에서 전체 관측치 수 중에서 각 카테고리가 차지하는 수의 비율을 제곱해서 빼줌
- 최대치 0.5(비율 50:50) / 하나의 범주로만 이루어진 순수한 데이터일 경우 0

지니계수로 정보 획득량 구하려면 가중치 부여해야 함

- 엔트로피(Entropy) : 지니 계수와 비슷하지만 이진 로그(Binary logarithm) 를 취함으로써 정규화 과정을 거침
- 범위 ( 0 ~ 1)


- 정보 획득량(Information gain) : 분류를 통해 지니 계수나 엔트로피가 증가 혹은 감소한 양
분류나무는 각 독립변수의 수치마다 지니 계수나 엔트로피 값을 구해서 최적의 정보 획득량을 얻을 수 있는 기준으로 분류 해 나감
-> 1회 자식 노드를 만들기 위해서 변수가 k개, 관측치가 n 개라고 했을 때, k(n-1) 번 계산
-> 정보 획득량이 없을 때까지 가지 뻗어나감

<회귀나무>
1. 종속변수가 연속형 변수이기 때문에 지니 계수나 엔트로피 대신 잔차 제곱합(Residual Sum of Square, RSS)등의 분류 기준 사용
- 그 밖의 분류 기준
-> F-value : 커지는 방향으로 자식 노드를 나눔(클수록 노드 간의 이질성이 높다는 뜻)
-> 분산의 감소량(Variance reduction) : 노드의 분산이 최소화되도록 자식 노드를 나눔(작을수록 한 노드에 속한 관측치의 동질성이 높다는 뜻)
2. 종속변수의 비선형성에 영향 받지 않음 -> 일반 선형회귀분석에 비해 모델 활용이 까다롭지 않음

-> 구역을 나누어 값을 예측하기 때문에 모델 사용 가능!
종속변수 Y의 잔차 제곱합이 최소화되는 구간을 구분하여 분기를 하는 방식으로 X1 활용
끝 노드에 속한 데이터 값의 평균을 구해 회귀 예측값을 계산 (붉은 선들이 예측값이 됨)
<의사결정나무 모델의 장단점>
장점
- 직관적 -> 해석의 용이성 -> 간단하게 분류, 예측을 구현할 수 있음
- 쿼리로도 쉽게 구현 가능
- 비선형 모델 -> 데이터의 선형성, 정규성, 등분산성 등이 필요하지 않음
단점
- 명목형 변수는 예측 데이터에 있는 정보가 학습 데이터에 없으면 예측이 불가능함
- 학습데이터에 있는 연속형 변수의 값만큼만 예측 데이터에 적용
- 예측할 수 있는 종속변수의 최소 최댓값은 학습 데이터의 범위에 한정됨 -> 학습데이터와 예측데이터의 연속형 변숫값 편차가 큰 경우 예측력이 떨어질 수 있음
- 학습데이터에 과적합될 확률 높음 -> 가지 분기될수록 학습 데이터에 대한 정확도 증가 -> 가지 너무 증가하면 일반화가 어려워짐
<의사결정나무 모델의 과적합 방지를 위한 방법>
- 가지치기(Pruning) : 모델의 분기 가지들을 적절히 쳐내어 과도하게 분기된 부분들을 없애주는 것(분기를 합치는 개념)
- 모델 정확도는 다소 떨어지더라도, 과적합을 방지하여 모델 일반화 가능
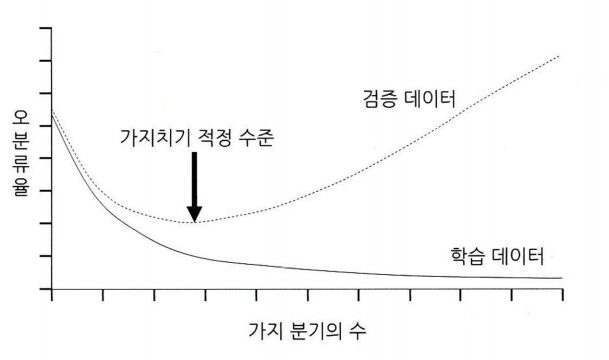
- 정보 획득량 임곗값(Threshold) 설정 : 분기를 했을 때 정보 획득량이 너무 적으면 분기를 멈추도록 설정
- 한 노드에 들어가는 최소 데이터 수 제한하기
- 노드의 최대 깊이 제한하기
<랜덤 포레스트>
의사결정나무 모델은 학습 성능의 변동이 크다는 고질적인 문제가 있음
: 랜덤 포레스트(Random Forest) : 나무를 여러 개 만들어서 학습
-> 다양한 상황을 고려하여 학습되기 때문에 과적합 방지 가능 -> 앙상블 학습(Ensemnle learning)


부트스트랩(Bootstrap) : 하나의 데이터셋을 중복 허용하여 무작위로 여러 번 추출하는 것(Step 1)
- 무작위로 선택할 독립변수의 수는 일반적으로 전체 독립변수 개수의 제곱근으로 함
배깅(Bagging) : 여러 개의 의사결정나무를 하나의 모델로 결합해 주는 것
- 분류 모델은 투표 방식(Voting) , 연속형 값의 예측 모델은 평균(Average)으로 집계
부스팅(Boosting) : 배깅이 모델의 일반화에 초점을 맞춘 방식이라면, 맞추기 어려운 문제를 맞히는 데 더 특화된 방식
- 각 트리모델을 순차적으로 학습하며 정답과 오답에 가중치를 부여해줌
- 보다 정밀한 예측이 가능하지만 과적합의 위험이 높으며, 이상치에 취약하다는 단점이 있음
<의사결정나무와 랜덤 포레스트 실습>
13-6. KNN(분류, 예측 모델)
K-근접이웃(K-Nearest Neighbors; KNN) : 학습 데이터의 별도 학습 과정 없이 미리 저장되어 있는 학습 데이터에다 예측 데이터를 대조함으로써 직접 결과가 도출됨(메모리 기반 학습(Memory-based learning))
- 공간상에 이웃해 있는 관측치의 범주나 값을 통해 결과를 출력함

- 데이터의 지역 구조(Local structure)에 민감함
-> 범주의 분포가 편향되어 있을 경우 예측 데이터의 관측치들이 빈도 높은 범주로 강하게 쏠리는 단점이 있음
- 이진 분류인 경우 홀수의 K로 설정하는 게 좋음
<최적의 K 선택 방법>
교차검증(cross validation) : 오분류율이 가장 낮아지는 K 수 탐색 ( K 수를 1부터 늘려가며 오분류율 변화 관찰)
-> 교차검증을 여러 번 수행하는 K-fold 교차검증을 하기도 함

<거리에 가중치 주는 방식 차이>
d가 이웃 관측치까지의 거리일 때

유클리드 거리(Euclidean distance)로 거리 계산

데이터 정규화/표준화를 반드시 해줘야함. (명목형 독립 변수의 경우에는 0과1로 더미 변수 처리하여 사용)
종속변수가 연속형 변수인 경우 회귀 나무처럼 KNN 회귀 사용
-> 안정된 모델을 만들기 위해서는 정확도가 다소 떨어지더라도 K를 3이상으로 설정해주는게 좋음
변수가 너무 많아지거나 데이터양이 커지면 연산량 증가가 다른 모델보다 훨씬 커 비효율적임
특정 하나의 범주가 대부분을 차지하고 있는 상황에서는 분류가 잘 되지 않음
<KNN 실습>
13-7. 시계열 분석(예측 모델)
시계열 분석 : 관측치의 통계량 변화를 시간의 흐름에 따라 순차적(Sequentially)으로 데이터화하고 현황을 모니터링하거나 미래의 수치를 예측하는 분석 방법
- 탐색 목적 : 외부 인자와 관련된 계절적인 패턴, 추세 등을 설명하고 인과관계를 규명
- 예측 목적 : 과거 데이터 패턴을 통해 미래의 값을 예측
시계열에서 한 시점의 관측 결과 X 는 시간 t에 따라 변동하는 값이며 신호와 잡음으로 이루어져있음



시계열 분해 : 위 처럼 시계열 요소로 나누는 것 (추세와 순환성을 합쳐서 추세라고 표현하기도 함)
<시계열 분해 방법>
- SEATS(Seasonal Extraction in ARIMA Time Series) 분해 방법
- STL(Seasonal and Trend decomposition using Loess) 방법
- 파이썬 seasonal_decompose 라이브러리 활용
<회귀 기반 시계열 분석>
비즈니스 분야에서 주로 사용되는 시계열 분석 기법
- 회귀 기반 방법
- 지수평활법
- ARIMA 모델 방법
회귀 기반 모델
- 예측하고자 하는 시점 t의 값이 종속변수 , t 시점에 해당하는 요소(해당 요일, 월 등)들이 독립변수가 됨
-> 요일, 월 등의 변수는 실제로는 더미변수로 변환해야 모델 학습 가능
- 해당 시점에 대한 요일이나 월 등에 대한 정보를 독립변수화함으로써 시즌성이나 순환성 모델에 반영 가능
- 증가/감소하는 추세성을 반영하려면 시계열이 시작하는 기준 시점일로부터의 경과일을 독립변수화하면 됨!

비선형 추세의 경우 다항회귀하여 모델의 적합성을 향상시킬 수 있음!
1. 해당 독립변수에 제곱을 취해 회귀선 보정

2. 독립변수나 종속변수에 로그을 취해 회귀선 보정
-> 변수에 0이 포함되어 있는 경우 log(x+1)과 같이 변환해줘야 함
-> 다른 일반 선형 모델과 비교하거나 예측값을 계산할 때 역산하여 기준에 맞춰줘야 함.
-> 과적합 위험이 있으므로 과도한 변수 변형은 주의 필요
<장점>
- 외부 요소를 변수로 추가해 주는 것이 용이(독립변수 추가)
-ex) 할인행사 유무, 공휴일/명절, 날씨, 경제지표, 과거 기간 수치
(자기회귀(Autoregression) 반영-> 시차이동에 따른 수치 변화에 대한 설명력 높일 수 있음)

- 자기상관함수 ACF(Autocorrelation function) : 시계열 데이터의 주기성을 수치적으로 확인할 수 있고 어떠한 특정 시차가 어떠한 영향을 주는지 알 수 있음
- 점선으로 되어있는 가로선을 벗어나면 해당 시차가 Y값과 상관성이 있다는 것을 의미
- 다소 주관적인 기준
- 선막대가 0보다 크면 양의 상관관계, 작으면 음의 상관관계

시계열 데이터에 추세가 존재할 경우, 근접한 시차에 대한 상관성은 높은 양의 값을 갖게 되는 경향이 있음
- 편자기상관함수 (PACF, Partical Autocorrelation function) : Y의 시점과 특정 시점 이외의 모든 시점과의 영향력을 배제한 순수한 영향력을 나타내는 척도
- 다른 시점들과의 다중공선성을 제거한 단 두 시점과의 관계를 수치화한 것
ARIMA 모델(Auto regressive integrated moving average)
- 이동평균을 누적한 자기회귀를 활용하여 시계열 분석을 하는 것
AR(자기회귀)모델, MA(이동평균)모형 분석 시작 전 시계열 데이터가 정상성(Stationarity)을 가지도록 변환해줘야 함
정상성: 모든 시점에 대해서 일정한 평균을 갖도록 하는 것
-> 추세나 계절성이 없는 시계열 데이터로 만들어 주는 것(평균과 분산이 안정되어 있는 상태)

추세에 있어 평균 일정치 않으면 차분(difference)해줌
- 차분 : 연달아 이어진 관측값들의 차이를 계산하여 그 변화 차이를 제거하는 것(현재 상태값 - 전 상태값)
- 1차 차분(일반 차분) : 추세만 차분
- 2차 차분(계절 차분) : 계절성도 존재하는 경우 계절성의 시차인 n 시점 전 값을 빼 주는 것
시계열 데이터의 분산이 일정치 않으면 변환(Transformation)해줌
- 각 시점의 값에 로그나 루트를 씌워 주어 분산의 크기를 완화시켜 줌 -> 시점 간 편차 감소

자기 회귀(AR) : 자기 자신에 대한 변수의 회귀 ( 회귀 기반 시계열 분석에서 시차 변수만 사용한 개념)

이동평균(MA) : 관측값의 이전 시점의 연속적인 예측 오차(Forecast error)의 영향을 이용하는 방법

두 모델 결합하면 자기회귀평균 모델 ARMA(p, q) (p, q는 시점의 수)
-> 추세를 가지고 있으며 일정한 패턴을 가지고 있지 않은 경우가 많음
ARMA 모델 자체의 불안정성을 제거하는 기법을 결합한 모델이 ARIMA 모델 ( ARIMA(p, d, q) )
- 과거의 데이터가 가지고 있던 추세까지 반영
- 시계열의 비정상성을 설명하기 위해 시점 간의 차분 사용

-> 시계열 데이터를 d화 차분하고 p만큼의 과거 값들과 q 만큼의 과거 오차 값들을 통해 수치를 예측하고 차분한 값을 다시 원래의 값으로 환산하여 최종 예측값을 산출
1. 시각화와 ACF 차트를 통해 시계열 데이터가 정상시계열인지 확인
2. 추세가 있어서 평균이 일정하지 않으면 차분을 하여 차분계수 d 구한다
3. ACF, PACF 값을 통해 p 값과 q 값을 설정하고 최종의 ARIMA 모델을 만든다
-> 실젯값과 예측값의 차이를 측정하여 모델의 적합도와 예측력을 평가
(검증할 데이터가 적은 편이기 때문에 슬라이딩 윈도우 기법을 사용하여 학습 및 검증 데이터 증폭시킬 수 있음)

<시계열 분석 실습>
13-8. k-means 클러스터링(군집 모델)
- 비지도학습이라 미리 가지고 있는 정답(레이블) 없이 데이터의 특성과 구조를 발견해 내는 방식
- k : 분류할 군집의 수
- means : 각 군집의 중심(Centroid), 각 관측치들 간의 거리 평균값으로 구함
- 중심점과 군집 내 관측치 간의 거리를 비용함수로 하여, 이 함수 값이 최소화되도록 중심점과 군집을 반복적으로 재정의해줌!
-> k 개의 중심점을 찍어서 관측치들 간의 거리를 최적화하여 군집화하는 모델 (데이터 표준화와 정규화 필수)


-> 지역 최솟값(Local minimum) 문제 발생 가능


<적절한 k 선정하기>
- 비즈니스 도메인 지식을 통한 개수 선정
- 엘보우 기법(Elbow method) : 군집 내 중심점과 관측치 간 거리 합이 급감하는 구간의 k 개수를 선정하는 방법

- 실루엣 계수(Silhouette coefficient) : 군집 안의 관측치들이 다른 군집과 비교해서 얼마나 비슷한지를 나타내는 수치, 동일한 군집 안에 있는 관측치들 간의 평균 거리와 가장 가까운 다른 군집과의 평균 거리를 구해 실루엣 계수를 구함

- 동일한 군집 내 관측치들 간 평균 거리가 집단 간 평균 거리보다 짧을수록 실루엣 계수 높아짐
- 1에 가까울수록 k 적합
<DBSCAN>
- 별도의 k 지정 필요 없음
- 관측치들의 밀도를 통해 자동으로 적절한 군집의 수를 찾음
밀도 측정
1. 기준 관측치로부터 이웃한 관측치인지 구별할 수 있는 거리 기준 필요
2. 거리 기준 내에 포함된 이웃 관측치 수(minPts)에 대한 기준이 필요

군집의 끝에 위치한 관측치들을 경계선(Border) 데이터라고 함
+) 군집 명확하지 않은 이상치 잘 분류 가능
-) 필요한 연산량이 많음
-) 데이터의 특성을 모를 경우 적절한 파라미터 값을 설정하는 것이 어려움
<k-means 클러스터링 실습>
'데이터 분석가가 반드시 알아야할 모든 것' 카테고리의 다른 글
| 서포트벡터머신, 연관규칙과 협업 필터링 (0) | 2024.05.01 |
|---|---|
| 모델 평가 (0) | 2024.04.10 |
| 데이터 분석하기 (0) | 2024.03.27 |
| 데이터 전처리와 파생변수 생성 (0) | 2024.03.20 |
| 데이터 탐색과 시각화 (0) | 2024.03.13 |