05장. 회원 탈퇴를 예측하는 테크닉 10
전제 조건
→ 스포츠 센터의 데이터

<041. 데이터를 읽어 들이고 이용 데이터를 수정하자>
import pandas as pd
customer = pd.read_csv('customer_join.csv')
uselog_months = pd.read_csv('use_log_months.csv')
미래를 예측하기 위해 그 달과 1개월 전의 이용 이력(횟수)만으로 데이터 작성
year_months = list(uselog_months["연월"].unique())
uselog = pd.DataFrame()
for i in range(1, len(year_months)):
tmp = uselog_months.loc[uselog_months["연월"]==year_months[i]]
tmp.rename(columns={"count":"count_0"}, inplace = True)
tmp_before = uselog_months.loc[uselog_months["연월"]==year_months[i-1]]
del tmp_before["연월"]
tmp_before.rename(columns={"count":"count_1"}, inplace=True)
tmp = pd.merge(tmp, tmp_before, on="customer_id", how="left")
uselog = pd.concat([uselog, tmp], ignore_index=True)
uselog.head()
count_0 : 현재 달
count_1 : 이전 달
<042. 탈퇴 전월의 탈퇴 고객 데이터를 작성하자>
이 데이터의 경우 탈퇴 월의 관계성이 아래와 같으므로, 탈퇴 월이 아닌 탈퇴 전월의 데이터를 작성함.

탈퇴한 회원을 추출하고, end_date의 1개월 전을 계산해 연월에 저장한 후 uselog와 결합
from dateutil.relativedelta import relativedelta
exit_customer = customer.loc[customer["is_deleted"]==1]
exit_customer["exit_date"] = None
exit_customer["end_date"] = pd.to_datetime(exit_customer["end_date"])
for i in range(len(exit_customer)):
exit_customer["exit_date"].iloc[i] = exit_customer["end_date"].iloc[i] - relativedelta(months=1)
exit_customer["연월"] = pd.to_datetime(exit_customer["exit_date"]).dt.strftime("%Y%m")
uselog["연월"] = uselog["연월"].astype(str)
exit_uselog = pd.merge(uselog, exit_customer, on=["customer_id", "연월"], how="left")
print(len(uselog))
exit_uselog.head()33851

exit_customer["exit_date"] = None
→ exit_customer 데이터프레임에 새로운 열 만들고, 모든 값을 None으로 초기화
exit_customer["exit_date"].iloc[i] = exit_customer["end_date"].iloc[i] - relativedelta(months=1)
→ relativedelta(months=1) : end_date에서 한 달 전 날짜를 계산해 줌
결측치 없는 데이터만 남기고 나머지 제거 → 특정 회원이 그만두기 전월의 상태를 나타내는 데이터
exit_uselog = exit_uselog.dropna(subset=["name"])
print(len(exit_uselog))
print(len(exit_uselog["customer_id"].unique()))
exit_uselog.head()1104
1104

exit_uselog = exit_uselog.dropna(subset=["name"])
→ name 열만을 기준으로 결측값을 확인하여 그 행 삭제
<043. 지속 회원의 데이터를 작성하자>
지속 회원은 탈퇴 월이 없기 때문에 어떤 연월의 데이터를 작성해도 상관 없음
conti_customer = customer.loc[customer["is_deleted"]==0]
conti_uselog = pd.merge(uselog, conti_customer, on=["customer_id"], how="left")
print(len(conti_uselog))
conti_uselog = conti_uselog.dropna(subset=["name"])
print(len(conti_uselog))33851
27422
name 칼럼의 결손 데이터를 제거해 탈퇴 회원 제거
탈퇴 데이터가 1104개밖에 없기 때문에 지속회원 데이터 27422개를 전부 사용한다면 불균형 데이터가 되어 버림
→ 한쪽의 데이터가 몇 %밖에 없는 경우 샘플의 수를 조정! (언더샘플링)
지속 회원 데이터가 회원 당 1개가 되도록 언더샘플링
conti_uselog = conti_uselog.sample(frac=1).reset_index(drop=True)
conti_uselog = conti_uselog.drop_duplicates(subset="customer_id")
print(len(conti_uselog))
conti_uselog.head()2842

conti_uselog = conti_uselog.sample(frac=1).reset_index(drop=True)
→ conti_uselog의 모든 행을 무작위로 섞음
→ sample(frac=1) : 전체 데이터(비율 1, 즉 100%)를 무작위로 샘플링하여 섞어주기 위해 사용
→ reset_index(drop=True) : 섞은 후 원래 인덱스 삭제 후, 새롭게 인덱스를 0부터 다시 부여(리셋)
conti_uselog = conti_uselog.drop_duplicates(subset="customer_id")
→ customer_id를 기준으로 중복된 행 제거(기본적으로 첮 번째로 등장한 중복 값을 남김)
- 지속 회원과 탈퇴 회원 데이터를 세로 결합
predict_data = pd.concat([conti_uselog, exit_uselog],ignore_index=True)
print(len(predict_data))
predict_data.head()
3946

<044. 예측할 달의 재적 기간을 작성하자>
- 재적 기간 데이터를 변수로 이용하기 위해 재적 기간 열 추가
predict_data["period"] = 0
predict_data["now_date"] = pd.to_datetime(predict_data["연월"], format="%Y%m")
predict_data["start_date"] = pd.to_datetime(predict_data["start_date"])
for i in range(len(predict_data)):
delta = relativedelta(predict_data["now_date"][i], predict_data["start_date"][i])
predict_data["period"][i] = int(delta.years*12 + delta.months)
predict_data.head()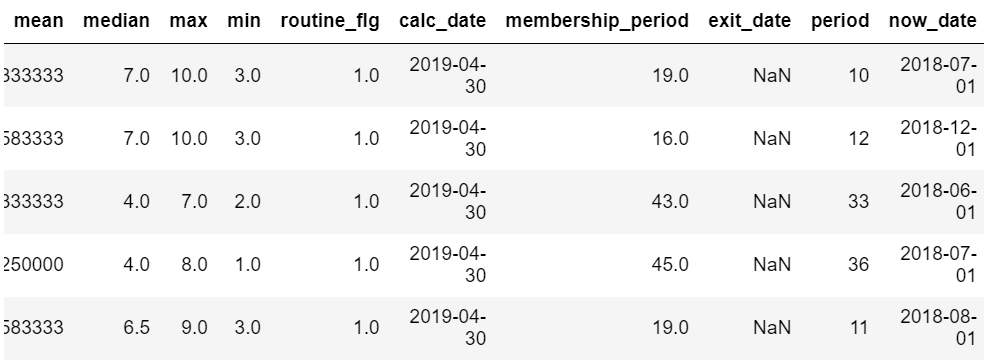
<045. 결측치를 제거하자>
결측치가 있으면 머신러닝할 수 없으므로 결측치 제거 or 채워야 함 → 제거 선택
- 결측치의 수 파악
predict_data.isna().sum()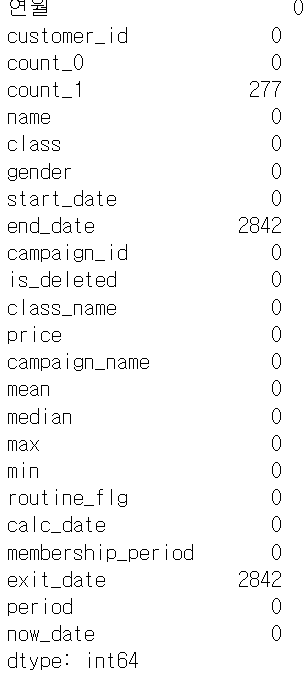
end_date와 exit_date는 탈퇴 고객만 있는 것이므로 유지 회원은 켤측치가 되는 게 당연
여기서는 count_1의 결손치만 제거
predict_data = predict_data.dropna(subset=["count_1"])
predict_data.isna().sum()
<046. 문자열 변수를 처리할 수 있게 가공하자>
머신러닝할 때 가입 캠페인 구분, 회원 구분, 성별과 같은 문자열 데이터 (카테고리 변수) 어떻게 처리하면 좋을까?
→ 플래그 만들기! (더미 변수 : 독립 변수를 0과 1로 변환한 변수)
target_col = ["campaign_name", "class_name", "gender", "count_1", "routine_flg", "period", "is_deleted"]
predict_data = predict_data[target_col]
predict_data.head()
특정 열만 선택해 새로운 데이터프레임 생성
→ 설명 변수로 1개월 전의 이용 횟수 count_1
→ 카테고리 변수 campaign_name, class_name, gender, 정기 이용 여부 플래그 routine_flg, 재적기간 period
→ 목적 변수로 탈퇴 플래그 is_deleted 사용
- 카테고리 변수를 이용해 더미 변수 만들기
predict_data = pd.get_dummies(predict_data)
predict_data.head()
pandas의 get_dummies를 이용해 일괄적으로 더미 변수 생성
- 겹치는 정보를 제거하기 위해 campaign_name_일반, class_name_야간, gender_M 삭제
del predict_data["campaign_name_일반"]
del predict_data["class_name_야간"]
del predict_data["gender_M"]
predict_data.head()<047. 의사결정 트리를 사용해서 탈퇴 예측 모델을 구축하자>
- 의사결정 트리 알고리즘을 사용해 모델 구축하기
from sklearn.tree import DecisionTreeClassifier
import sklearn.model_selection
exit = predict_data.loc[predict_data["is_deleted"]==1]
conti = predict_data.loc[predict_data["is_deleted"]==0].sample(len(exit))
X = pd.concat([exit, conti], ignore_index=True)
y = X["is_deleted"]
del X["is_deleted"]
X_train, X_test, y_train, y_test = sklearn.model_selection.train_test_split(X,y)
model = DecisionTreeClassifier(random_state=0)
model.fit(X_train, y_train)
y_test_pred = model.predict(X_test)
print(y_test_pred)
- 1은 탈퇴, 0은 유지를 의미
- from sklearn.tree import DecisionTreeClassifier
→ Decision Tree 분류 모델을 사용하기 위해 sklearn 라이브러리에서 DecisionTreeClassifier 임포트
- import sklearn.model_selection
→ train_test_split 함수 사용을 위해 sklearn.model_selection 모듈 임포트
- conti = predict_data.loc[predict_data["is_deleted"]==0].sample(len(exit))
→ exit 데이터프레임과 같은 크기로 무작위 샘플링하여 모델 편향 방지
- fit으로 학습용 데이터를 사용해 모델 구축
- predict로 평가 데이터 예측
- 실제 정답 비교
results_test = pd.DataFrame({"y_test":y_test ,"y_pred":y_test_pred })
results_test.head()
<048. 예측 모델을 평가하고 모델을 튜닝해 보자>
- results_test 데이터를 집계해 정답률 계산하기
correct = len(results_test.loc[results_test["y_test"]==results_test["y_pred"]])
data_count = len(results_test)
score_test = correct / data_count
print(score_test)0.8973384030418251
약 90% 정도의 정확도!
학습용 데이터로 예측한 정확도와 평가용 데이터로 예측한 정확도의 차이가 작은 것이 이상적임
print(model.score(X_test, y_test))
print(model.score(X_train, y_train))0.8973384030418251
0.9790874524714829
train data에 과적합인 경향이 있음!
→ 데이터 늘리기, 변수 재검토, 모델의 파라미터 변경 등의 방법을 적용해 이상적인 모델로 만들 수 있음
모델의 파라미터 바꾸기
→ 의사결정 트리는 0과 1로 분할할 수 있는 설명 변수와 그 조건에 맞는 트리 구조를 찾는 방법이므로, 트리의 깊이를 얕게 하면 모델을 단순화할 수 있음
X = pd.concat([exit, conti], ignore_index=True)
y = X["is_deleted"]
del X["is_deleted"]
X_train, X_test, y_train, y_test = sklearn.model_selection.train_test_split(X,y)
model = DecisionTreeClassifier(random_state=0, max_depth=5)
model.fit(X_train, y_train)
print(model.score(X_test, y_test))
print(model.score(X_train, y_train))0.9106463878326996
0.9334600760456274
max_depth를 5로 지정해 트리 깊이 제한
<049. 모델에 기여하는 변수를 확인하자>
- 변수와 중요도 저장 → 변수의 기여율 확인
importance = pd.DataFrame({"feature_names":X.columns, "coefficient":model.feature_importances_})
importance
- model.feature_importances_
→ 학습된 의사결정 나무 모델이 각 특징에 부여한 중요도 값을 coefficient 열에 저장
- 1개월 전의 이용 횟수, 정기 이용 여부, 재적 기간이 크게 기여함을 알 수 있음
의사결정 트리 결과 가시화
→ graphviz, plot_tree와 같은 라이브러리 이용
from sklearn.tree import plot_tree
import matplotlib.pyplot as plt
plt.figure(figsize=(20,10)) # 그래프 크기 설정
plot_tree(model,
feature_names=list(X.columns),
class_names=["Not Deleted", "Deleted"],
filled=True, #색 채우기
rounded=True,
fontsize=10) # 폰트 크기 설정
plt.show()
<050. 회원 탈퇴를 예측하자>
- 예측을 위한 데이터 작성
count_1 = 3
routing_flg = 1
period = 10
campaign_name = "입회비무료"
class_name = "종일"
gender = "M"
- 데이터 가공
→ 카테고리 변수를 if 문으로 분기하면서 더미 변수로 작성
if campaign_name == "입회비반값할인":
campaign_name_list = [1, 0]
elif campaign_name == "입회비무료":
campaign_name_list = [0, 1]
elif campaign_name == "일반":
campaign_name_list = [0, 0]
if class_name == "종일":
class_name_list = [1, 0]
elif class_name == "주간":
class_name_list = [0, 1]
elif class_name == "야간":
class_name_list = [0, 0]
if gender == "F":
gender_list = [1]
elif gender == "M":
gender_list = [0]
input_data = [count_1, routing_flg, period]
input_data.extend(campaign_name_list)
input_data.extend(class_name_list)
input_data.extend(gender_list)
범주형 데이터를 원핫 인코딩 (One-Hot Encoding) 방식으로 변환하여 input_data 리스트에 추가
인코딩(encoding) / 부호화 : 데이터의 양을 줄이기 위해 데이터를 코드화하고 압축, 변형하는 것
디코딩(decoding) : 압축, 변형된 데이터를 원형으로 변환하는 것
원핫(one-hot) : 비트들의 모임 중 하나만 1이고 나머지는 모두 0인 비트들의 그룹
원핫 인코딩 : 데이터를 one-hot 데이터 형태로 변형, 압축하는 것
→ 범주의 개수에 따라 벡터의 크기 달라짐
from sklearn.preprocessing import OneHotEncoderprint(model.predict([input_data])) # 0 또는 1로 예측된 클래스 반환
print(model.predict_proba([input_data])) # 각 클래스에 속할 확률 반환[1.]
[[0.01492537 0.98507463]]
- 1, 즉 탈퇴가 예상됨
06장. 물류의 최적경로를 컨설팅하는 테크닉 10
전제 조건
→ 부품을 보관하는 창고에서 생산 공장으로 부품 운송
→ 각 창고와 공장 구간의 운송 비용은 과거 데이터에서 정량적으로 계산되어 있음
→ 집계 기간 2019년 1월 1일 ~ 2019년 12월 31일
→ 북부지사와 남부지사의 데이터를 csv로 제공

<051. 물류 데이터를 불러오자>
import pandas as pd
# 공장데이터 불러오기
factories = pd.read_csv("tbl_factory.csv", index_col=0)
factories
# 창고데이터 불러오기
warehouses = pd.read_csv("tbl_warehouse.csv", index_col=0)
warehouses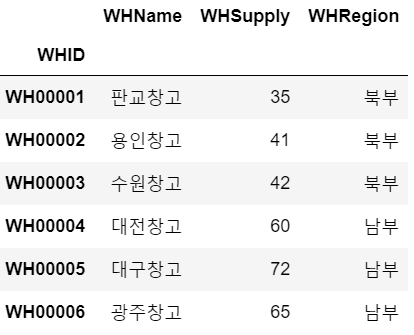
# 비용 테이블
cost = pd.read_csv("rel_cost.csv", index_col=0)
cost.head()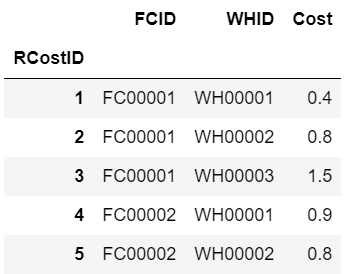
# 운송 실적 테이블
trans = pd.read_csv("tbl_transaction.csv", index_col=0)
trans.head()
- index_col=0
→ csv 파일의 첫 번째 열을 데이터프레임의 인덱스로 설정
- 공장 데이터 'FCID'와 창고 데이터 "'WHID' 가 키임을 알 수 있음
→ 운석 실적을 중심으로 각 정보 결합(레프트 조인)
join_data = pd.merge(trans, cost, left_on=["ToFC","FromWH"], right_on=["FCID","WHID"], how="left")
join_data.head()
- 운송 실적 테이블에 비용 데이터 추가
- 운송 실적 데이터의 도착 공장(ToFC), 출발 창고(FromWH)와 비용 데이터의 공장ID(FCID)와 창고ID(WHID)를 키로 결합
join_data = pd.merge(join_data, factories, left_on="ToFC", right_on="FCID", how="left")
join_data.head()
- 공장 정보 추가
- ToFC 열과 FCID의 열이 일치하는 데이터를 찾아 병합
→ 일치하지 않는 경우 오른쪽 데이터프레임의 값은 NaN으로 채워짐(left 조인)
join_data = pd.merge(join_data, warehouses, left_on="FromWH", right_on="WHID", how="left")
join_data = join_data[["TransactionDate","Quantity","Cost","ToFC","FCName","FCDemand","FromWH","WHName","WHSupply","WHRegion"]]
join_data.head()
- 창고 정보 추가, 컬럼 정리
- 순서대로 운송 날짜, 운송 수량, 비용, 공장ID, 공장명, 공장수요, 창고ID, 창고명, 창고 공급량, 지사
- 연결에 사용했던 키는 필요 없으니 데이터에서 삭제
- 지사 별로 데이터를 비교하기 위해 각각 해당하는 데이터만 추출해서 변수에 저장
north = join_data.loc[join_data["WHRegion"]=="북부"]
north.head()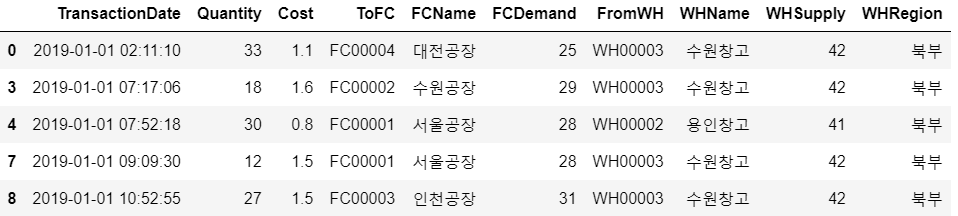
- 북부 데이터 추출
south = join_data.loc[join_data["WHRegion"]=="남부"]
south.head()
-남부 데이터 추출
<052. 현재 운송량과 비용을 확인해 보자>
- 1년간 운송한 부품 수와 비용 집계
print("북부지사 총비용: " + str(north["Cost"].sum()) + "만원")
print("남부지사 총비용: " + str(south["Cost"].sum()) + "만원")북부지사 총비용: 2189.3만원
남부지사 총비용: 2062.0만원
- 1년간 운송 비용을 sum으로 집계
- 북부지사 쪽이 운송 비용의 총액이 많이 소요되는 것을 알 수 있음
print("북부지사의 총부품 운송개수: " + str(north["Quantity"].sum()) + "개")
print("남부지사의 총부품 운송개수: " + str(south["Quantity"].sum()) + "개")북부지사의 총부품 운송개수: 49146개
남부지사의 총부품 운송개수: 50214개
- 1년간의 운송 실적으로 실제로 운송한 부품의 수 집계
- 남부지사 쪽이 많은 부품을 운송하고 있음을 알 수 있음
tmp = (north["Cost"].sum() / north["Quantity"].sum()) * 10000
print("북부지사의 부품 1개당 운송 비용: " + str(int(tmp)) + "원")
tmp = (south["Cost"].sum() / south["Quantity"].sum()) * 10000
print("남부지사의 부품 1개당 운송 비용: " + str(int(tmp)) + "원")북부지사의 부품 1개당 운송 비용: 445원
남부지사의 부품 1개당 운송 비용: 410원
- 부품 1개당 운송 비용 계산 → 남부지사 쪽이 1개당 운송 비용이 낮음을 알 수 있음
cost_chk = pd.merge(cost, factories, on="FCID", how="left")
print("북부지사의 평균 운송 비용:" + str(cost_chk["Cost"].loc[cost_chk["FCRegion"]=="북부"].mean()) + "원")
print("남부지사의 평균 운송 비용:" + str(cost_chk["Cost"].loc[cost_chk["FCRegion"]=="남부"].mean()) + "원")북부지사의 평균 운송 비용:1.075원
남부지사의 평균 운송 비용:1.05원
- cost와 factories 데이터를 FICD 열을 기준으로 병합
- 비용을 지사별로 집계 후 평균 → 평균 운송 비용은 거의 같으므로, 남부지사 쪽이 효율 높게 부품을 운송하고 있다는 것을 알 수 있음
<053. 네트워크를 가시화해 보자>
최적 경로를 가시화하는 방법인 네트워크 가시화
→ NetworkX
import networkx as nx
import matplotlib.pyplot as plt
# 그래프 객체생성
G=nx.Graph()
# 노드 설정
G.add_node("nodeA")
G.add_node("nodeB")
G.add_node("nodeC")
# 엣지 설정
G.add_edge("nodeA","nodeB")
G.add_edge("nodeA","nodeC")
G.add_edge("nodeB","nodeC")
# 좌표 설정
pos={}
pos["nodeA"]=(0,0)
pos["nodeB"]=(1,1)
pos["nodeC"]=(0,1)
# 그리기
nx.draw(G,pos)
# 표시
plt.show()
- 그래프 객체 선언 후 노드와 각각을 연결할 엣지 설정
→ networkx : 그래프(네트워크)를 생성하고 노드와 엣지를 다루기 위한 라이브러리
- pos로 노드의 좌표를 설정하고 draw 함수를 이용해 그리기
- matplotlib의 함수 show 사용해서 그래프를 화면에 표시
- 이 흐름으로 네트워크를 가시화해서 창고에서 대리점까지의 물류를 표현할 수 있음
→ 물류의 쏠림과 같은 전체 그림 파악 가능
<054. 네트워크에 노드를 추가해 보자>
G.add_node("nodeD")
G.add_edge("nodeA", "nodeD")
pos["nodeD"]=(1,0)
nx.draw(G, pos, with_labels = True)
- with_labels=True
→ 각 노드에 레이블이 표시되도록 설정
- dict 형식으로 pos에 위치 추가
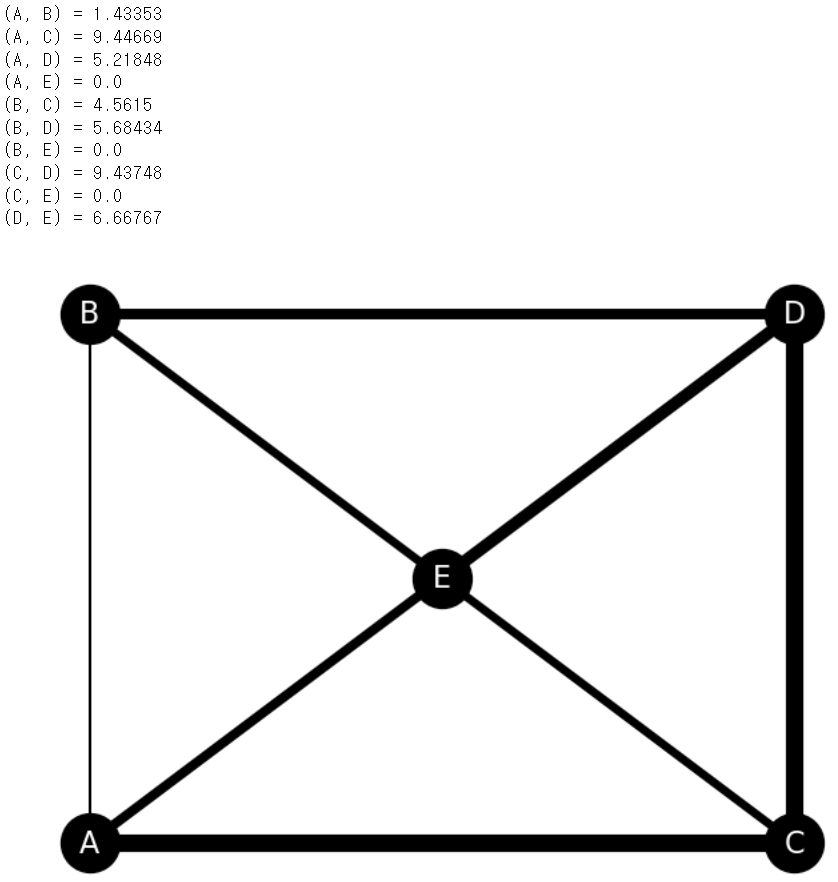
<055. 경로에 가중치를 부여하자>
가중치를 이용해 노드 사이의 엣지 굵기를 바꿈으로써 물류의 최적 경로를 알기 쉽게 가시화할 수 있음
→ csv 파일에 저장된 가중치 정보를 데이터프레임으로 읽어 들여 사용하는 방법을 이용해보자!


import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import networkx as nx
# 데이터 불러오기
df_w = pd.read_csv('network_weight.csv')
df_p = pd.read_csv('network_pos.csv')
# 그래프 객체 생성
G = nx.Graph()
# 노드 설정
for i in range(len(df_w.columns)):
G.add_node(df_w.columns[i])
# 엣지 설정 & 가중치 리스트화
size = 10
edge_weights = []
num_pre = 0
# 엣지 가중치 확인용 번역자 추가 코드
name = ['A','B','C','D','E']
for i in range(len(df_w.columns)):
for j in range(len(df_w.columns)):
if not (i==j):
# 엣지 추가
G.add_edge(df_w.columns[i],df_w.columns[j])
if num_pre<len(G.edges):
num_pre = len(G.edges)
# 엣지 가중치 추가
edge_weights.append(df_w.iloc[i][j]*size)
# 엣지 가중치 확인용 번역자 추가 코드
print(f'({name[i]}, {name[j]}) = {np.round(edge_weights[-1],5)}')
# 좌표 설정
pos = {}
for i in range(len(df_w.columns)):
node = df_w.columns[i]
pos[node] = (df_p[node][0],df_p[node][1])
# 그리기
nx.draw(G, pos, with_labels=True,font_size=16, node_size = 1000, node_color='k', font_color='w', width=edge_weights)
# 표시
plt.show()
for i in range(len(df_w.columns)):
G.add_node(df_w.columns[i])- df_w의 열 이름을 사용해 각 노드를 그래프에 추가
size = 10
edge_weights = []
num_pre = 0
name = ['A', 'B', 'C', 'D', 'E']- 엣지의 가중치를 저장할 리스트 생성
- 현재까지 추가된 엣지 수를 추적하기 위한 num_pre 변수 설정
- name : 엣지 가중치를 출력하기 위한 노드 이름 리스트
for i in range(len(df_w.columns)):
for j in range(len(df_w.columns)):
if not (i==j):
G.add_edge(df_w.columns[i], df_w.columns[j])
if num_pre < len(G.edges):
num_pre = len(G.edges)
edge_weights.append(df_w.iloc[i][j] * size)
print(f'({name[i]}, {name[j]}) = {np.round(edge_weights[-1], 5)}')- 두 노드 간의 엣지 추가, 가중치를 edge_weights 리스트에 부여
- df_w.iloc[i][j] * size : 가중치 값에 size 변수를 곱해 엣지의 두께를 더 강조함
- 새 엣지가 추가될 때만 가중치를 저장
- 소수점 5자리까지 반올림하여 출력
pos = {}
for i in range(len(df_w.columns)):
node = df_w.columns[i]
pos[node] = (df_p[node][0], df_p[node][1])- 노드의 좌표를 저장하는 딕셔너리 생성
- df_p에서 각 노드의 x, y 좌표를 가져와 pos 딕셔너리에 저장
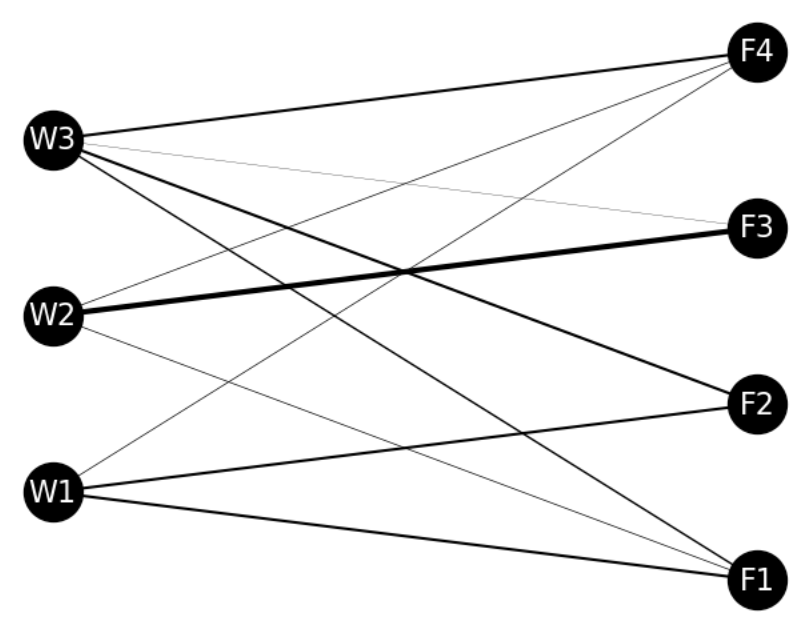
<056. 운송 경로 정보를 불러오자>

제품의 부품을 저장한 창고 W1, W2, W3에서 조립 공장 F1, F2, F3, F4로 필요한 부품을 운송
import pandas as pd
df_tr = pd.read_csv('trans_route.csv', index_col="공장")
df_tr.head()
<057. 운송 경로 정보로 네트워크를 가시화해 보자>
import pandas as pd
import matplotlib.pyplot as plt
import networkx as nx
df_tr = pd.read_csv('trans_route.csv', index_col="공장")
df_pos = pd.read_csv('trans_route_pos.csv')
# 그래프 객체 생성
G = nx.Graph()
# 노드 설정
for i in range(len(df_pos.columns)):
G.add_node(df_pos.columns[i])
# 엣지 설정 및 가중치 리스트화
num_pre = 0
edge_weights = []
size = 0.1
for i in range(len(df_pos.columns)):
for j in range(len(df_pos.columns)):
if not (i==j):
# 엣지 추가
G.add_edge(df_pos.columns[i],df_pos.columns[j])
# 엣지 가중치 추가
if num_pre<len(G.edges):
num_pre = len(G.edges)
weight = 0
if (df_pos.columns[i] in df_tr.columns)and(df_pos.columns[j] in df_tr.index):
if df_tr[df_pos.columns[i]][df_pos.columns[j]]:
weight = df_tr[df_pos.columns[i]][df_pos.columns[j]]*size
elif(df_pos.columns[j] in df_tr.columns)and(df_pos.columns[i] in df_tr.index):
if df_tr[df_pos.columns[j]][df_pos.columns[i]]:
weight = df_tr[df_pos.columns[j]][df_pos.columns[i]]*size
edge_weights.append(weight)
# 좌표 설정
pos = {}
for i in range(len(df_pos.columns)):
node = df_pos.columns[i]
pos[node] = (df_pos[node][0],df_pos[node][1])
# 그리기
nx.draw(G, pos, with_labels=True,font_size=16, node_size = 1000, node_color='k', font_color='w', width=edge_weights)
# 표시
plt.show()
if (df_pos.columns[i] in df_tr.columns) and (df_pos.columns[j] in df_tr.index):
if df_tr[df_pos.columns[i]][df_pos.columns[j]]:
weight = df_tr[df_pos.columns[i]][df_pos.columns[j]] * size
elif (df_pos.columns[j] in df_tr.columns) and (df_pos.columns[i] in df_tr.index):
if df_tr[df_pos.columns[j]][df_pos.columns[i]]:
weight = df_tr[df_pos.columns[j]][df_pos.columns[i]] * size
edge_weights.append(weight)- 노드 간의 경로가 존재할 경우 가중치 계산
- 골고루 엣지가 보임 → 운송 비용을 생각하면 운송 경로는 어느 정도 집중되는 편이 효율이 높을 수 있음
<058. 운송 비용 함수를 작성하자>
최적화 문제를 푸는 패턴
- 최소화(또는 최대화)하고 싶은 것을 함수로 정의 (목적 함수)
- 최소화(또는 최대화)를 함에 있어 지켜야 할 조건 정의 (제약 조건)
- 생각할 수 있는 여러 가지 조합 중에서 제약 조건을 만족시키면서 목적함수를 최소화(또는 최대화)하는 조합 선택
가설 : 운송 비용을 낮출 효율적인 운송 경로가 존재한다.
→ 이 가설을 입증하고 운송 경로를 최적화하기 위해 먼저 운송 비용을 계산할 함수를 작성하고 목적함수로 정의
import pandas as pd
# 데이터 불러오기
df_tr = pd.read_csv('trans_route.csv', index_col="공장")
df_tc = pd.read_csv('trans_cost.csv', index_col="공장")
# 운송 비용 함수
def trans_cost(df_tr,df_tc):
cost = 0
for i in range(len(df_tc.index)):
for j in range(len(df_tr.columns)):
cost += df_tr.iloc[i][j]*df_tc.iloc[i][j]
return cost
print("총 운송 비용:"+str(trans_cost(df_tr,df_tc)))총 운송 비용:1493
- 운송 경로의 운송량과 비용을 곱하고 전부 더해서 총 운송 비용을 계산
- 함수로 미리 작성함으로써, 변경 후 운송 비용을 간단히 계산할 수 있도록 함
<059. 제약 조건을 만들어보자>
- 각 창고는 공급 가능한 부품 수에 제한이 있음
- 각 공장은 채워야 할 최소한의 제품 제조량이 있음
import pandas as pd
# 데이터 불러오기
df_tr = pd.read_csv('trans_route.csv', index_col="공장")
df_demand = pd.read_csv('demand.csv')
df_supply = pd.read_csv('supply.csv')
# 수요측 제약조건
for i in range(len(df_demand.columns)):
temp_sum = sum(df_tr[df_demand.columns[i]])
print(str(df_demand.columns[i])+"으로 운송량:"+str(temp_sum)+" (수요량:"+str(df_demand.iloc[0][i])+")")
if temp_sum>=df_demand.iloc[0][i]:
print("수요량을 만족시키고있음")
else:
print("수요량을 만족시키지 못하고 있음. 운송경로 재계산 필요")
# 공급측 제약조건
for i in range(len(df_supply.columns)):
temp_sum = sum(df_tr.loc[df_supply.columns[i]])
print(str(df_supply.columns[i])+"부터의 운송량:"+str(temp_sum)+" (공급한계:"+str(df_supply.iloc[0][i])+")")
if temp_sum<=df_supply.iloc[0][i]:
print("공급한계 범위내")
else:
print("공급한계 초과. 운송경로 재계산 필요")F1으로 운송량:30 (수요량:28)
수요량을 만족시키고있음
F2으로 운송량:30 (수요량:29)
수요량을 만족시키고있음
F3으로 운송량:32 (수요량:31)
수요량을 만족시키고있음
F4으로 운송량:25 (수요량:25)
수요량을 만족시키고있음
W1부터의 운송량:35 (공급한계:35)
공급한계 범위내
W2부터의 운송량:40 (공급한계:41)
공급한계 범위내
W3부터의 운송량:42 (공급한계:42)
공급한계 범위내
- 각 공장으로 운반되는 부품의 수와 각 공장에 대한 수요량을 비교하면 공장에서 제조된 제품의 수가 수요량을 만족시키는지 여부를 검토할 수 있음
- 각 창고에서 출하되는 부품의 수가 창고의 공급 한계를 넘는지를 검토할 수 있음
- temp_sum = sum(df_tr[df_demand.columns[i]])
→ 각 수요지로 운송되는 총 운송량 계산
- temp_sum = sum(df_tr.loc[df_supply.columns[i]])
→ 각 공급 공장에서 운송된 총 운송량 계산
<060. 제약 조건을 만들어보자>
- 시험 삼아 W1에서 F4로의 운송을 줄이고, 그만큼을 W2에서 F2로의 운송으로 보충하게 변경한 경로가 저장된 trans_route_new.csv를 불러들여 이 경로가 제약 조건을 만족시키는지, 어느 정도 비용 개선이 가능한지 확인, 계산
import pandas as pd
import numpy as np
# 데이터 불러오기
df_tr_new = pd.read_csv('trans_route_new.csv', index_col="공장")
print(df_tr_new)
# 총 운송비용 재계산
print("총 운송 비용(변경 후):"+str(trans_cost(df_tr_new,df_tc)))
# 제약조건 계산함수
# 수요측
def condition_demand(df_tr,df_demand):
flag = np.zeros(len(df_demand.columns))
for i in range(len(df_demand.columns)):
temp_sum = sum(df_tr[df_demand.columns[i]])
if (temp_sum>=df_demand.iloc[0][i]):
flag[i] = 1
return flag
# 공급측
def condition_supply(df_tr,df_supply):
flag = np.zeros(len(df_supply.columns))
for i in range(len(df_supply.columns)):
temp_sum = sum(df_tr.loc[df_supply.columns[i]])
if temp_sum<=df_supply.iloc[0][i]:
flag[i] = 1
return flag
print("수요조건 계산결과:"+str(condition_demand(df_tr_new,df_demand)))
print("공급조건 계산결과:"+str(condition_supply(df_tr_new,df_supply))) F1 F2 F3 F4
공장
W1 15 15 0 0
W2 5 0 30 10
W3 10 15 2 15
총 운송 비용(변경 후):1428
수요조건 계산결과:[1. 1. 1. 1.]
공급조건 계산결과:[1. 0. 1.]
def condition_demand(df_tr, df_demand):
flag = np.zeros(len(df_demand.columns))
for i in range(len(df_demand.columns)):
temp_sum = sum(df_tr[df_demand.columns[i]])
if temp_sum >= df_demand.iloc[0][i]:
flag[i] = 1
return flag- 각 수요지에 대한 조건이 충족되었는지의 여부를 0과 1로 저장하는 배열 생성(초기 값을 0으로 설정)
- 운송 비용 함수로 바로 계산 (비용 절감)
- 공급 조건 제약 조건 만족 못함
'파이썬 데이터 분석 실무 테크닉 100' 카테고리의 다른 글
| 01장(웹에서 주문 수를 분석하는 테크닉), 02장(대리점 데이터를 가공하는 테크닉) (2) | 2024.09.18 |
|---|