01장. 웹에서 주문 수를 분석하는 테크닉 10
목적 : 어떤 기업 쇼핑몰 사이트의 상품 주문 수의 추세를 분석함으로써 판매량 개선의 방향을 찾는 것
전제 조건
→ 이 쇼핑몰의 주요 품목은 컴퓨터
→ 가격대별로 5개의 상품 존재
→ 4종류의 6개 데이터

데이터베이스에 들어 있는 데이터를 시스템에서 가져올 때는 월별이나 1,000건 단위로 분할하는 경우가 많음
→ 데이터를 결합해 사용해야 함
<001. 데이터를 읽어 들이자>
# 경고(warning) 비표시
import warnings
warnings.filterwarnings('ignore')import pandas as pd
customer_master = pd.read_csv('customer_master.csv')
customer_master.head()

- 파이썬 라이브러리 판다스(pandas) 임포트
- pandas의 read_csv를 사용해 프레임형 변수 customer_master에 저장
- 읽어 들인 customer_master의 처음 5행 표시
item_master = pd.read_csv('item_master.csv')
item_master.head()
transaction_1 = pd.read_csv('transaction_1.csv')
transaction_1.head()
transaction_detail_1 = pd.read_csv('transaction_detail_1.csv')
transaction_detail_1.head()
→ 데이터를 확인함으로써 어떤 데이터가 존재하고 각 데이터 간에 어떤 관계가 있는지와 같은 데이터의 큰 틀 확인 가능
먼저 데이터 전체를 파악하는 것이 중요하기 때문에 되도록 상세하게 나와 있는 쪽에 맞춰 데이터 가공
→ 이 사례의 경우, 매출과 연관이 있고, 가장 상세한 데이터는 매출 관련 데이터이므로 transaction_detail을 기준으로 생각
→ 크게 2가지의 데이터 가공이 필요
- transaction_detail_1, transaction_detail_2 / transaction_1, transaction_2 세로 결합(유니언)
- transaction_detial을 기준으로, transaction, customer_master, item_master 가로 결합(조인)
<002. 데이터를 결합(유니언)해 보자>
transaction_2 = pd.read_csv('transaction_2.csv')
transaction = pd.concat([transaction_1, transaction_2], ignore_index = True)
transaction.head()
- pd.concat으로 유니언
- head()로는 유니언이 잘 됐는지 확인 불가 → 세로 결합이므로 데이터 개수로 유니언 검증 필요
- ignore_index = Ture : 이를 무시하지 않으면 이전 데이터에 있던 index를 그대로 가져옴, 특별히 인덱스를 유지해야 하는 경우가 아니라면 옵션을 추가함 (↔ index = )
print(len(transaction_1))
print(len(transaction_2))
print(len(transaction))
transaction_detail_2 = pd.read_csv('transaction_detail_2.csv')
transaction_detail = pd.concat([transaction_detail_1, transaction_detail_2], ignore_index = True)
transaction_detail.head()
- transaction_detail도 유니언
<003. 매출 데이터끼리 결합(조인)해 보자>
기준이 되는 데이터를 결정하고 어떤 칼럼을 키로 조인할지 생각해야 함 → transaction_detail을 기준 데이터로 결정
- 부족한(추가하고 싶은) 데이터 칼럼이 무엇인가
→ transaction의 payment_date, customer_id 추가, price는 추가 x (quantity와 item_price의 곱으로 알 수 있음)
- 공통되는 데이터 칼럼은 무엇인가
→ transaction_id
join_data = pd.merge(transaction_detail, transaction[["transaction_id", "payment_date", "customer_id"]], on="transaction_id", how = "left")
join_data.head()
- pd.merge 로 조인
- transaction_detial을 기준으로
- 조인키(join key)는 결합할 transaction 데이터의 필요한 칼럼 transaction_id
- 조인 종류 : Left Join으로 지정
print(len(transaction_detail))
print(len(transaction))
print(len(join_data))
→ 세로로 데이터가 늘어나지 않고 가로로 늘어나 조인된 것을 확인할 수 있음
→ 조인할 데이터의 조인키(transaction_id)에 중복 데이터가 존재하는 경우 데이터 개수가 늘어날 수 있음
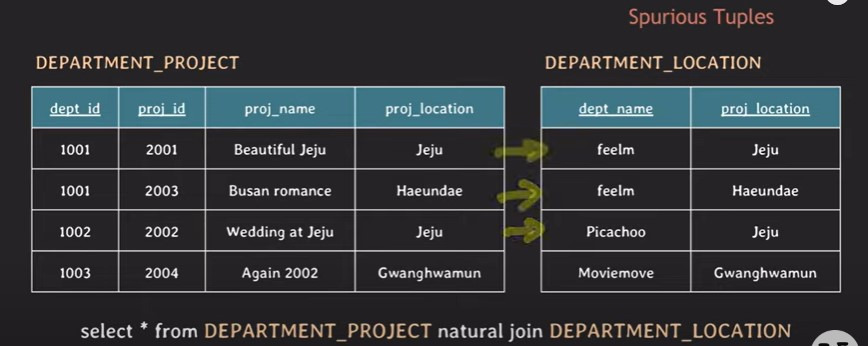
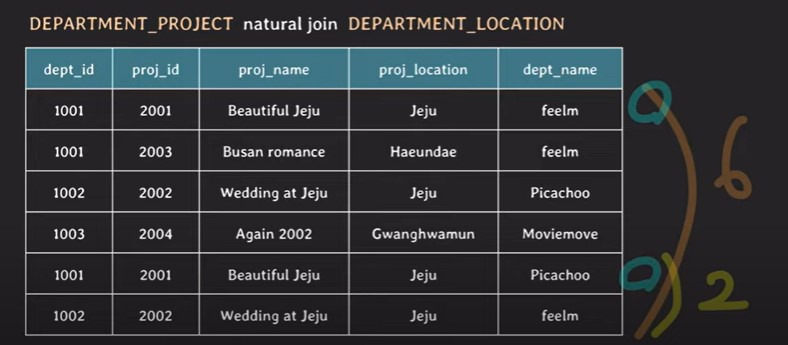
<부록 001. 데이터 결합과 정규화>
데이터 정규화 : 데이터를 관리하는 데이터베이스 설계 개념 중 하나로, '데이터의 정합성'을 담보하는 설계 사상
→ 데이터 정규화의 진행 정도에 따라 비정규화, 제1정규화, 제2정규화, 제3정규화로 분류
제1정규화 - 도메인 원자값 조건 만족 필요
- 반복 그룹 존재하면 안됨
- 모든 행은 식별자로 완전하게 구분되어야 함
제2정규화 - 부분함수 종속 제거
- key가 아닌 값들은 모두 key에 종속되어야 함
제3정규화 - 이행적 함수 종속 제거
- 모든 non-key 컬럼은 key 컬럼에만 종속되어야 함
결합 : 데이터를 합치는 것
- 내부 결합(inner join) : 결합할 2개의 데이터에 모두 존재하는 데이터로만 구성
→ 정확하게 결합 조건을 설정하지 않으면 데이터 누락이 생길 수 있음
- 외부 결합(outer join) : 어느 한 쪽만 존재하면 데이터 결합 가능
→ 레프트 조인(결합되는 쪽의 좌측 데이터가 모두 사용됨), 라이트 조인(결합되는 쪽의 우측 데이터가 모두 사용됨) 포함
→ 데이터 1에만 있는 데이터의 데이터 2 부분에는 NULL이 들어감
<004. 마스터데이터를 결합(조인)해 보자>
- 부족한(추가하고 싶은) 데이터 칼럼이 무엇인가
→ customer_master, item_master에 포함된 데이터
- 공통되는 데이터 칼럼은 무엇인가
→ 각각 customer_id, item_id
join_data = pd.merge(join_data, customer_master, on = "customer_id", how = 'left')
join_data = pd.merge(join_data, item_master, on = "item_id", how = 'left')
join_data.head()
- 결합의 영향으로 매출(price)이 사라졌기 때문에 다시 계산해야 함
<005. 필요한 데이터 칼럼을 만들자>
매출 = quantity x item_price
join_data["price"] = join_data["quantity"] * join_data["item_price"]
join_data[["quantity", "item_price", "price"]].head()
- 판다스의 데이터프레임형 곱셈 : 행마다(가로 방향) 계산 실행
<006. 데이터를 검산하자>
검산이 가능한 데이터 칼럼을 찾고 검산하기 : 이번 사례는 price 칼럼
print(join_data["price"].sum())
print(transaction["price"].sum())
데이터 가공 전 transaction의 price 총합과 데이터 가공 후 price 총합이 같음
join_data["price"].sum() == transaction["price"].sum()
#True
True / False로도 확인 가능
<007. 각종 통계량을 파악하자>
데이터 분석을 진행할 때는 크게 두 가지를 파악해야 함
- 결손치의 개수 : 제거하거나 보간해야 함
- 전체를 파악할 수 있는 숫자감 : 이번 달 상품 A의 매출이 10만원 → 전체 매출 단위 10억/100만원인지로 의미 달라짐
join_data.isnull().sum()
- 결손치의 개수 출력
- isnull()은 결손치가 True/False로 반환되기 때문에 True의 개수를 칼럼마다 sum()으로 계산
- 결손치 없음
join_data.describe()

- describe()를 이용해 데이터 개수(count), 평균값(mean), 표준편차(std), 최솟값(min), 사분위수(25%, 75%), 중앙값(50%), 최댓값(max) 각종 통계량 출력 가능
- describe()는 숫자 데이터를 집계함
print(join_data["payment_date"].min())
print(join_data["payment_date"].max())
- 데이터의 기간 파악 가능
<008. 월별로 데이터를 집계해 보자>
시계열 상황 살펴보기
- 이번 케이스처럼 반년 정도의 데이터라면 별로 영향이 없겠지만, 과거 수년의 데이터에는 여러가지 비즈니스 모델이 포함되어 있을 수 있기 때문에 전체 데이터를 한 번에 분석하면 데이터의 시계열 변화를 잘못 파악하는 경우가 있을 수 있음
→ 데이터 범위를 좁혀 분석하는 것도 하나의 방법!
전체적으로 매출 변화를 파악해보기
- 구입일 payment_date에서 연월을 추출해 새롭게 칼럼을 작성하고, 연월 단위로 price 집계해서 표시
join_data.dtypes
- 데이터타입 확인
- payment_date는 object형
join_data["payment_date"] = pd.to_datetime(join_data["payment_date"])
join_data["payment_month"] = join_data["payment_date"].dt.strftime("%Y%m")
join_data[["payment_date", "payment_month"]].head()
- datetime형으로 데이터 타입 변환 (to_datetime)
- 새로운 칼럼 payment_month를 연월 단위로 작성
→ 판다스의 datetime의 dt를 사용하면 년, 월 추출 가능
→ strftime을 사용해 연월 작성
- datetime object에 dt 접근자를 사용해 datetime 속성이나 메서드를 사용해 시계열 데이터를 처리할 수 있음
- dt.strftime() : pandas의 datetime object를 지정된 date format으로 변환

from datetime import datetime
# 현재 날짜
now = datetime.now()
# 특정 형식의 문자열로 변환
formatted_date = now.strftime('%d-%m-%Y %H:%M:%S')
print(formatted_date)
#result = sr.dt.strftime('% d % m % Y, % r')
%Y : 연도 0001~9999
%m : 달 01~12
%d : 날짜 01~31
%H : 24시간 형식의 하루의 시간 00~23
%I : 12시간 형식의 하루의 시간 01~12
%M : 분 00~59
%S : 초 00~59
join_data.groupby("payment_month").sum()["price"]

- 월별 매출 집계
- groupby : 집계하고 싶은 칼럼(payment_month)과 집계 방법(sum) 기술, price만 표시하기 위해 price 칼럼 지정
→ 5월 매출이 조금 내려갔지만, 6월, 7월 회복, 가장 매출이 높은 달은 7월 등의 정보를 알 수 있음
데이터프레임.groupby(그룹이되는컬럼)[계산하고 싶은 컬럼].집계함수()
or
데이터프레임.groupby(그룹이되는컬럼).집계함수()[계산하고 싶은 컬럼]
<집계함수(집계 방법) 종류>
- mean(평균), median(중위수)
- count(개수), sum(합산)
- min(최소), max(최대)
- std(표준편차), var(분산), quantile(특정 백분위)
(ex. df.groupby("월")["야근"].quantile(0.9) ← 월별 상위 10% 야근일수)
- describe(전반적인 지표)
< multiple column / groupby >
데이터프레임.groupby([컬럼1,컬럼2]).agg({계산하고싶은컬럼명1 : 집계함수 , 계산하고싶은컬럼명2 : 집계함수})
ex. 월별 인당 휴일 평균과 야근 총합
df.groupby(["월","이름"]).agg({"휴일":"mean","야근":"sum"})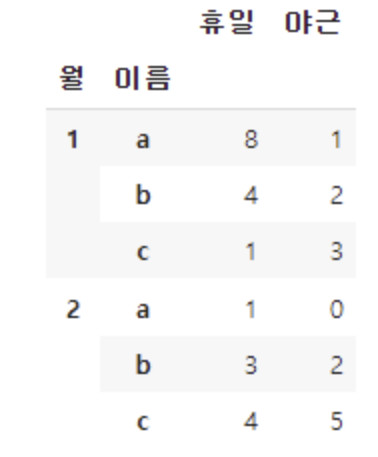
< reset_index로 index 초기화해서 데이터 활용하기 >
g1_df["이름"] #컬럼명 자체가 인덱스로 들어가 있기 때문에 오류 발생g2_df = df.groupby(["월", "이름"]).agg({"휴일":"mean", "야근":"sum"}).reset_index()
g2_df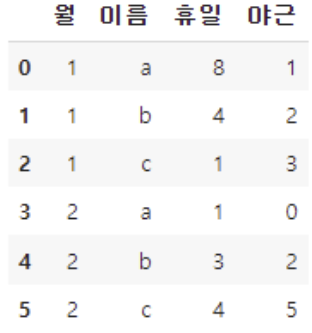
<009. 월별, 상품별로 데이터를 집계해 보자>
월별, 상품별로 매출의 합계, 수량 표시
join_data.groupby(["payment_month", "item_name"]).sum()[["price", "quantity"]]
- 월별, 상품별로 price와 quantity의 집계 결과 표시
- groupby에서 출력하고 싶은 칼럼이 여러 개 있을 경우, 리스트형으로 지정
pd.pivot_table(join_data, index='item_name', columns='payment_month', values=['price', 'quantity'], aggfunc='sum')
- pivot_table로 행과 칼럼 지정 가능
- 행에는 상품명, 칼럼에는 월이 오도록 index와 columns로 지정
- values에는 집계하고 싶은 칼럼(price, quantity) 지정
- aggfunc에는 집계 방법(sum) 지정
- 월별, 상품별로 추세 파악하기 쉬움
→ 매출 합계는 PC-E가 가장 높지만, 수량에서는 가장 싼 PC-A가 많음, 5월 매출 감소의 원인은 PC-E의 영향이 큼
pandas.pivot_table(data, values=None, index=None, columns=None, aggfunc='mean', fill_value=None, margins=False, dropna=True, margins_name='All', observed=_NoDefault.no_default, sort=True)
- fill_value : 집계 후, 결과 피벗 테이블에서 누락된 값을 바꿀 값
- margins = True : 행과 열의 범주에 부분 그룹 집계가 적용되어 특수 열과 행 추가(여백)
- dropna = True : 모든 열에 NaN 값이 있는 행은 마진 계산 전 생략
- sort : 결과 정렬 여부 지정
<010. 상품별 매출 추이를 가시화해 보자>
월별, 상품별 매출 추이 그래프로 표현
- 데이터 집계
- 집계된 데이터를 이용해 그래프 그리기
graph_data = pd.pivot_table(join_data, index='payment_month', columns='item_name', values='price', aggfunc='sum')
graph_data.head()
- pivot_table를 이용해 데이터 집계
- 그래프를 그리기 위해 가로축에 payment_month, 세로축에 graph_data의 해당 상품명 지정
import matplotlib.pyplot as plt # from matplotlib import pyplot as plt
%matplotlib inline
plt.plot(list(graph_data.index), graph_data["PC-A"], label='PC-A')
plt.plot(list(graph_data.index), graph_data["PC-B"], label='PC-B')
plt.plot(list(graph_data.index), graph_data["PC-C"], label='PC-C')
plt.plot(list(graph_data.index), graph_data["PC-D"], label='PC-D')
plt.plot(list(graph_data.index), graph_data["PC-E"], label='PC-E')
plt.legend()
- matplotlib 임포트
→ 가로축, 세로축 순서로 지정
→ 가로축은 payment_month를 표시해야 하므로 graph_data.index를 리스트형으로 변환하여 지정
→ 세로축은 상품별 매출로 graph_data 칼럼을 지정
→ label로 범례 표시
- 상품마다 그래프를 그리고, legend()는 범례 표시
- %matplotlib inline : notebook을 실행한 브라우저에서 바로 그림을 볼 수 있도록 브라우저 내부에 그려지도록 함
→ 도표, 그래프, 그림, 소리, 애니메이션 등과 같은 산출물(Rich output)을 표현하는 방법 중 하나
- plt.legend() : 그래프에 범례 추가 (plot 함수 안에 입력한 label이 사용)
→ plt.legend(('Y1', 'Y2')) 와 같이 legend 함수 안에 label 직접 입력 가능
02장. 대리점 데이터를 가공하는 테크닉 10
전제조건
→ 상품 A~Z까지 26개의 상품 취급
→ 매출 이력과 고객정보 데이터는 담당사원이 시스템에 직접 입력 : '지저분한 데이터'

<011. 데이터를 읽어 들이자>
import pandas as pd
uriage_data = pd.read_csv("uriage.csv")
uriage_data.head()
- item_name, item_price에 결측치/오류 확인 가능
kokyaku_data = pd.read_excel("kokyaku_daicho.xlsx")
kokyaku_data.head()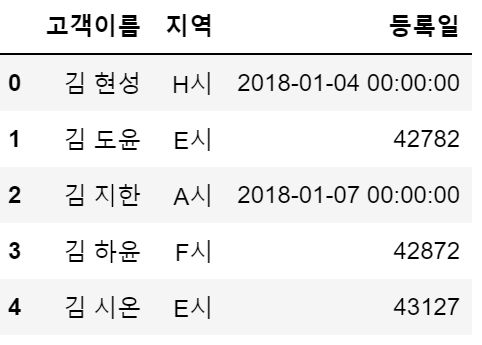
→ 데이터의 정합성에 문제가 있음 : 입력 오류나 표기 방법의 차이가 부정합을 일으킴
ex) 날짜 포맷 차이, 공백 유무
→ 정합성을 갖추기 위해 데이터의 속성과 의미를 이해하고 데이터의 오류를 파악해야 함
<012. 데이터의 오류를 살펴보자>
- 매출 이력에서 item_name을 추출해 데이터 오류 확인
uriage_data["item_name"].head()
- 공백, 대소문자 섞여있음
uriage_data["item_price"].head()
- 결측치 NaN 확인 가능
<013. 데이터에 오류가 있는 상태로 집계해 보자>
데이터 정합성의 중요성 파악
- 매출 이력 데이터에서 상품별로 월 매출 합계 집계
uriage_data["purchase_date"] = pd.to_datetime(uriage_data["purchase_date"])
uriage_data["purchase_month"] = uriage_data["purchase_date"].dt.strftime("%Y%m")
res = uriage_data.pivot_table(index = "purchase_month", columns = "item_name", aggfunc = "size", fill_value = 0)
res
- 날짜를 연월 형태로 반환
- pivot_table로 행(구입 연월)와 칼럼(삼품 이름) 지정
→ 상품의 건수로 집계
- aggfunc로 집계 방법(size) 지정
- fill_value = 0 : 집계 후, 결과 피벗 테이블에서 누락된 값을 바꿀 값을 0으로 설정
- 동일한 상품이 다른 상품으로 집계됨, 26개의 상품이 99개의 상품으로 늘어남
res = uriage_data.pivot_table(index = "purchase_month", columns = "item_name", values = "item_price", aggfunc = "sum", fill_value = 0)
res
- values로 집계하고 싶은 칼럼(item_price)을 지정해서 집계
→ 데이터 가공 없이 집계 및 분석을 실시하면 의미 없는 결과가 나옴!
<014. 상품명 오류를 수정하자>
- 공백 오류 수정하기
print(len(pd.unique(uriage_data.item_name)))99
→ 26개의 상품이 99개로 늘어나 있음
- len + pd.unique로 매출 이력의 item_name의 중복을 제외한 데이터 건수 확인 가능
print(uriage_data["item_name"].nunique())
- len + pd.unique를 nunique로 대체 가능
- 데이터 오류 수정하기
uriage_data["item_name"] = uriage_data["item_name"].str.upper()
uriage_data["item_name"] = uriage_data["item_name"].str.replace(" ", "")
uriage_data["item_name"] = uriage_data["item_name"].str.replace(" ", "")
uriage_data.sort_values(by = ["item_name"], ascending = True)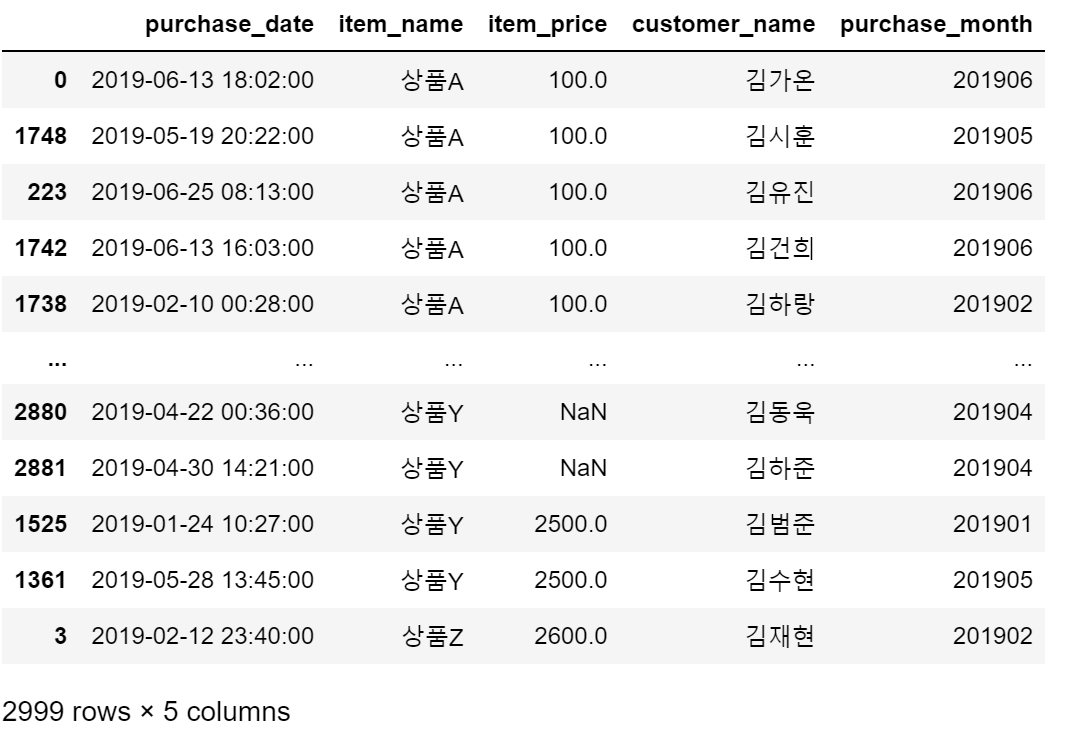
- str.upper()로 소문자를 대문자로 변환
- str.replace()로 공백 제거
- item_name을 기준으로 정렬해 화면에 표시
<문자열 내장 함수>
문자열.replace(기존 값, 변경할 값, 변경횟수)
문자열.upper() : 소문자를 대문자로 변환
문자열.lower() : 대문자를 소문자로 변환
print(len(pd.unique(uriage_data["item_name"])))
print(pd.unique(uriage_data["item_name"]))
<015. 금액의 결측치를 수정하자>
상품 단가가 집계 중에 변하지 않았기 때문에 프로그램으로 결측치 수정 가능
- 결측치 확인하기
uriage_data.isnull().any(axis = 0)
- isnull() 을 이용해 매출 이력 데이터의 결측치 유무 확인 가능
- item_price에 결측치가 있음을 확인할 수 있음
- 데이터프레임.isnull() : 데이터프레임에서 결측치가 있는지 확인
→ 결측치 있으면 True, 없으면 False로 표시
- any() : True가 하나라도 존재하는지 확인하는 함수
axis = 0 : 열(column)단위로 연산 → 각 열을 기준으로, 해당 열에 하나라도 결측치가 있으면 True, 그렇지 않으면 False 반환하므로 이를 통해 열별로 결측값이 존재하는지 여부 확인 가능
axis=1 : 행(row) 단위로 연산 → 각 행을 기준으로 계산
- all() : 모든 값이 True일 때만 True 반환
- 결측치 수정하기
→ 집계 기간에 상품 단가의 변동이 없다는 전제조건이 있으므로, 같은 상품의 단가를 이용해 수정 가능
flg_is_null = uriage_data["item_price"].isnull()
for trg in list(uriage_data.loc[flg_is_null, "item_name"].unique()):
price = uriage_data.loc[(~flg_is_null) & (uriage_data["item_name"] == trg), "item_price"].max()
uriage_data["item_price"].loc[(flg_is_null) & (uriage_data["item_name"] == trg)] = price
uriage_data.head()
- item_price 중에 결측치 있는 곳 조사하여 flg_is_null 변수에 저장 (True, False로 저장)
- list(uriage_data.loc[flg_is_null, "item_name"].unique()) : flg_is_null을 이용해 결측치가 있는 상품명 리스트 작성
→ list() : 변수의 값을 리스트 형식으로 변환
→ loc 함수 : 조건이 일치하는 데이터 추출
- '금액에 결측치가 있다'를 조건으로 하기 위해 flg_is_null로 조건 지정 (flg_is_null이 True 인 행)
- 조건과 일치하는 데이터 중에서 어떤 칼럼(item_name)을 가져올지 지정 가능
→ 결측치가 존재하는 상품명 추출
- unique() : 추출한 상품명에서 중복을 제거하여 고유한 상품명 리스트 제작
- price = uriage_data.loc[(~flg_is_null) & (uriage_data["item_name"] == trg), "item_price"].max()
→ 결측치가 있는 상품과 같은 상품이며 금액이 올바르게 입력된 행을 loc으로 찾고, 그 금액을 가져옴
- loc()의 조건 : 부정 연산자 ~을 이용 ( flg_is_null == False )
- 현재 상품의 결측치가 없는 item_price 값 중에서 최대값을 찾아 결측치를 채우기 위해 price에 저장
- uriage_data["item_price"].loc[(flg_is_null) & (uriage_data["item_name"] == trg)] = price
→ 가져온 금액으로 데이터 수정
- 매출 이력의 item_price 칼럼에서 loc()으로 결측치가 있는 데이터 추출 후, 금액 데이터 price로 대체
→ 결측치가 있는 상품명에 대해 위에서 찾은 최대 가격을 해당 상품의 결측치에 할당
- 검증하기
uriage_data.isnull().any(axis = 0)
- item_price 의 결측치가 없어진 것을 확인 가능
for trg in list(uriage_data["item_name"].sort_values().unique()):
print(trg + "의최고가:" + str(uriage_data.loc[uriage_data["item_name"]==trg]["item_price"].max())
+ "의최저가:" + str(uriage_data.loc[uriage_data["item_name"]==trg]["item_price"].min(skipna=False)))
- 모든 상품에 대해 반복문 처리
- 모든 상품의 최대금액과 최소금액이 일치하는 것으로 봐서 성공적으로 금액을 수정했다는 것을 알 수 있음
→ skipna : NaN의 무시 여부 설정 가능 , False로 지정하여 NaN이 존재할 경우 최솟값이 NaN으로 표시되도록 함
<016. 고객 이름의 오류를 수정하자>
- 데이터 확인하기
kokyaku_data["고객이름"].head()
uriage_data["customer_name"].head()
- 두 데이터 서식이 일치하지 않으므로 결합 불가능
kokyaku_data["고객이름"] = kokyaku_data["고객이름"].str.replace(" ", "")
kokyaku_data["고객이름"] = kokyaku_data["고객이름"].str.replace(" ", "")
kokyaku_data["고객이름"].head()
- str.replace()로 고객 정보의 고객 이름에서 공백 제거
f. 같은 이름의 데이터가 존재하는 경우 등록일, 생년월일 등 다른 정보를 이용해서 구분해야 함
<017. 날짜 오류를 수정하자>
- 고객 등록일 오류 수정하기
엑셀 데이터로, 서식이 다른 데이터가 섞여 있을 수 있으니 주의 필요
- 날짜 동일한 포맷으로 통일하기
flg_is_serial = kokyaku_data["등록일"].astype("str").str.isdigit()
flg_is_serial.sum()22
- str.isdigit() : 고객 정보의 등록일이 숫자인지 아닌지 판정
→ 숫자로 된 곳을 flg_is_serial에 저장
.astype("str") : 열의 값을 모두 문자열로 변환
→ 날짜 데이터의 경우 문자열로 변환하고, 결측치(NaN)은 "nan"이라는 문자열로 변환
str.isdigit() : 각 문자열이 숫자로만 이루어졌는지 확인하는 함수
→ 문자열의 모든 문자가 숫자(0~9)로만 이루어졌다면 True를, 그렇지 않다면 False를 반환
→ 공백, 기호, 날짜형식(ex. 2022-08-15), 결측치(NaN) 등은 Flase
fromSerial = pd.to_timedelta(kokyaku_data.loc[flg_is_serial, "등록일"].astype("float"), unit="D") + pd.to_datetime("1900/01/01")
fromSerial
엑셀에서 사용하는 시리얼 날짜 형식을 변환하여 Pandas에서 처리하는 과정
(엑셀에서 날짜는 1900년 1월 1일부터의 경과일수를 숫자로 기록하는 방식으로 표현하므로, 이 시리얼 넘버를 실제 날짜로 변환해야 함)
→ loc() : flg_is_serial이 True인 행의 "등록일" 값 추출 ( 숫자로만 이루어진 시리얼 날짜 값 선택)
- .astype("float") : 추출한 "등록일" 값을 실수형으로 변환
→ 엑셀 시리얼 날짜 값은 거의 정수로 표현되지만, 소수점을 포함하여 시간을 나타낼 수 있기에 실수형으로 변환하는 것이 적합 (ex. 2.5 = 1900년 1월 2일 오후 12시)
- pd.to_timedelta() 함수 : 시간의 차이를 표현하는 함수
→ unit ="D" : 일(Day) 단위로 계산한다는 의미
→ 일 단위로 숫자를 날짜로 변환
- pd.to_datetime("1900/01/01") : 1900/01/01 을 1로 기준 날짜 설정
→ 시리얼 넘버로 계산된 시간 차이에 '+' 로 더함으로써 실제 날짜 계산
<이틀이 어긋난 이유>

fromSerial = pd.to_timedelta(kokyaku_data.loc[flg_is_serial, "등록일"].astype("float") - 2, unit="D") + pd.to_datetime("1900/01/01")
fromSerial
- 엑셀 숫잣값에서 2를 빼서 처리
fromString = pd.to_datetime(kokyaku_data.loc[~flg_is_serial, "등록일"])
fromString
- 날짜로 변환된 데이터도 서식 통일
- 2018/01/04와 같이 슬래시로 구분된 서식을 하이픈으로 구분된 서식으로 통일하기 위한 처리 과정
- ~flg_is_serial : 부정 연산자 ~로 Flase인 것을 loc()함수의 조건으로 설정
→ 숫자가 아닌 값들로 이루어진 데이터도 pd.to_datetime을 이용해 날짜 형식으로 변환
kokyaku_data["등록일"] = pd.concat([fromSerial, fromString])
kokyaku_data
- 숫자를 날짜로 수정한 데이터(fromSerial)와 서식을 변경한 데이터(fromString)를 결합해서 데이터 갱신
kokyaku_data["등록연월"] = kokyaku_data["등록일"].dt.strftime("%Y%m")
rslt = kokyaku_data.groupby("등록연월").count()["고객이름"]
print(rslt)
print(len(kokyaku_data))
- 수정한 날짜에서 strftime을 이용해 등록연월을 작성하고 groupby()로 집계
데이터프레임.groupby(그룹이되는컬럼).집계함수()[계산하고 싶은 컬럼]
→ groupby 후, count()로 데이터 개수 집계
flg_is_serial = kokyaku_data["등록일"].astype("str").str.isdigit()
flg_is_serial.sum()0
- 등록일 칼럼에 숫자 데이터가 남아 있는지 다시 확인해보면 모든 숫자 데이터가 날짜로 잘 수정되었다는 것을 알 수 있음!
<018. 고객 이름을 키로 두 개의 데이터를 결합(조인)하자>
join_data = pd.merge(uriage_data, kokyaku_data, left_on="customer_name", right_on="고객이름", how="left")
join_data = join_data.drop("customer_name", axis=1)
join_data
- pd.merge() : 두 개의 데이터의 서로 다른 열을 지정하여 결합
- left_on 의 인수로 uriage_data의 customer_name 칼럼을 키로, right_on의 인수로 kokyaku_data의 고객 이름 칼럼을 키로 지정
- how로 결합 방법을 left로 지정 ( uriage_data을 기준으로 일치하는 kokyaku_data를 결합 )
- join_data.drop("customer_name", axis=1)
→ "고객 이름"과 중복되는 customer_name 열 제거
데이터 정제 완료!
<019. 정제한 데이터를 덤프하자>
정제한 데이터를 파일로 출력(덤프)해두고, 분석할 때 위 파일을 읽어 들이는 형식으로 데이터 분석 진행
- 먼저 칼럼의 배치를 다루기 쉽게 조정하기
dump_data = join_data[["purchase_date", "purchase_month", "item_name", "item_price", "고객이름", "지역", "등록일"]]
dump_data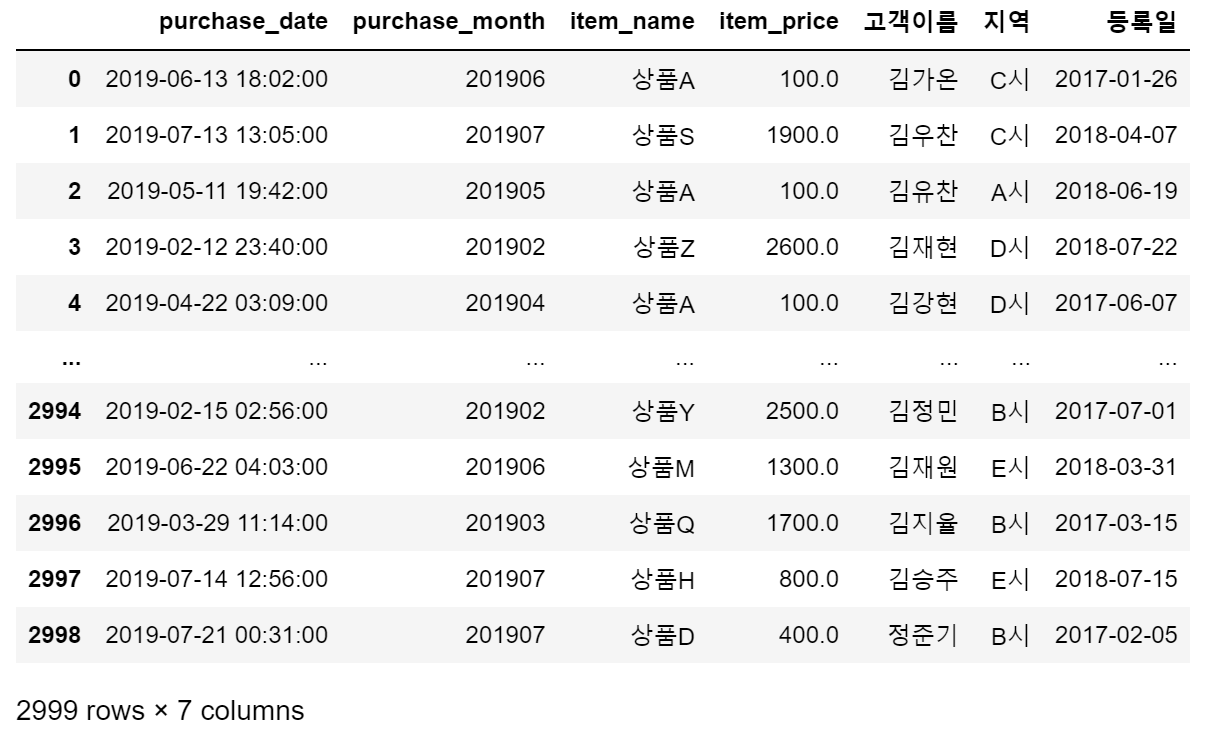
- join_data에서 필요한 칼럼을 임의의 순서로 정렬 후, dump_data에 저장
dump_data.to_csv("dump_data.csv", index=False)
- to_csv를 이용해 파일로 출력
<020. 데이터를 집계하자>
import_data = pd.read_csv("dump_data.csv")
import_data
- 덤프 데이터 불러오기
byItem = import_data.pivot_table(index="purchase_month", columns="item_name", aggfunc="size", fill_value=0)
byItem
- purchase_month를 세로축으로 상품별로 집계
byPrice = import_data.pivot_table(index="purchase_month", columns="item_name", values="item_price", aggfunc="sum", fill_value=0)
byPrice
- purchase_month를 세로축으로 매출금액별로 집계
byCustomer = import_data.pivot_table(index="purchase_month", columns="고객이름", aggfunc="size", fill_value=0)
byCustomer
- purchase_month를 세로축으로 고객별로 집계
byRegion = import_data.pivot_table(index="purchase_month", columns="지역", aggfunc="size", fill_value=0)
byRegion
- purchase_month를 세로축으로 지역별로 집계
away_data = pd.merge(uriage_data, kokyaku_data, left_on="customer_name", right_on="고객이름", how="right")
away_data[away_data["purchase_date"].isnull()][["고객이름", "등록일"]]
- 집계 기간에 구매 이력이 없는 사용자 확인
- right join으로 결합
→ 집계 기간 내에 구매하지 않은 고객은 NaN으로 채워짐
'파이썬 데이터 분석 실무 테크닉 100' 카테고리의 다른 글
| 05장(회원 탈퇴를 예측하는 테크닉), 06장(물류의 최적경로를 컨설팅하는 테크닉) (2) | 2024.10.02 |
|---|